Editor’s note: This post is part of our AI Decoded series, which aims to demystify AI by making the technology more accessible, while showcasing new hardware, software, tools and accelerations for RTX PC and workstation users.
If AI is having its iPhone moment, then chatbots are one of its first popular apps.
They’re made possible thanks to large language models, deep learning algorithms pretrained on massive datasets — as expansive as the internet itself — that can recognize, summarize, translate, predict and generate text and other forms of content. They can run locally on PCs and workstations powered by NVIDIA GeForce and RTX GPUs.
LLMs excel at summarizing large volumes of text, classifying and mining data for insights, and generating new text in a user-specified style, tone or format. They can facilitate communication in any language, even beyond ones spoken by humans, such as computer code or protein and genetic sequences.
While the first LLMs dealt solely with text, later iterations were trained on other types of data. These multimodal LLMs can recognize and generate images, audio, videos and other content forms.
Chatbots like ChatGPT were among the first to bring LLMs to a consumer audience, with a familiar interface built to converse with and respond to natural-language prompts. LLMs have since been used to help developers write code and scientists to drive drug discovery and vaccine development.
But the AI models that power those functions are computationally intensive. Combining advanced optimization techniques and algorithms like quantization with RTX GPUs, which are purpose-built for AI, helps make LLMs compact enough and PCs powerful enough to run locally — no internet connection required. And a new breed of lightweight LLMs like Mistral — one of the LLMs powering Chat with RTX — sets the stage for state-of-the-art performance with lower power and storage demands.
Why Do LLMs Matter?
LLMs can be adapted for a wide range of use cases, industries and workflows. This versatility, combined with their high-speed performance, offers performance and efficiency gains across virtually all language-based tasks.
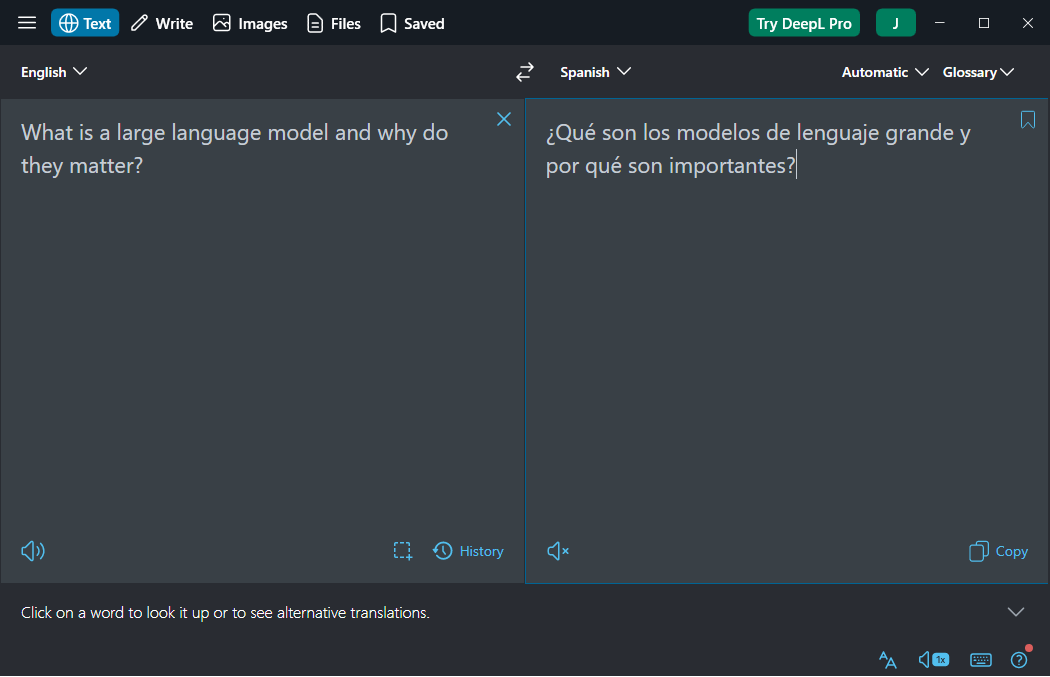
LLMs are widely used in language translation apps such as DeepL, which uses AI and machine learning to provide accurate outputs.
Medical researchers are training LLMs on textbooks and other medical data to enhance patient care. Retailers are leveraging LLM-powered chatbots to deliver stellar customer support experiences. Financial analysts are tapping LLMs to transcribe and summarize earning calls and other important meetings. And that’s just the tip of the iceberg.
Chatbots — like Chat with RTX — and writing assistants built atop LLMs are making their mark on every facet of knowledge work, from content marketing and copywriting to legal operations. Coding assistants were among the first LLM-powered applications to point toward the AI-assisted future of software development. Now, projects like ChatDev are combining LLMs with AI agents — smart bots that act autonomously to help answer questions or perform digital tasks — to spin up an on-demand, virtual software company. Just tell the system what kind of app is needed and watch it get to work.
Learn more about LLM agents on the NVIDIA developer blog.
Easy as Striking Up a Conversation
Many people’s first encounter with generative AI came by way of a chatbot such as ChatGPT, which simplifies the use of LLMs through natural language, making user action as simple as telling the model what to do.
LLM-powered chatbots can help generate a draft of marketing copy, offer ideas for a vacation, craft an email to customer service and even spin up original poetry.
Advances in image generation and multimodal LLMs have extended the chatbot’s realm to include analyzing and generating imagery — all while maintaining the wonderfully simple user experience. Just describe an image to the bot or upload a photo and ask the system to analyze it. It’s chatting, but now with visual aids.
Future advancements will help LLMs expand their capacity for logic, reasoning, math and more, giving them the ability to break complex requests into smaller subtasks.
Progress is also being made on AI agents, applications capable of taking a complex prompt, breaking it into smaller ones, and engaging autonomously with LLMs and other AI systems to complete them. ChatDev is an example of an AI agent framework, but agents aren’t limited to technical tasks.
For example, users could ask a personal AI travel agent to book a family vacation abroad. The agent would break that task into subtasks — itinerary planning, booking travel and lodging, creating packing lists, finding a dog walker — and independently execute them in order.
Unlock Personal Data With RAG
As powerful as LLMs and chatbots are for general use, they can become even more helpful when combined with an individual user’s data. By doing so, they can help analyze email inboxes to uncover trends, comb through dense user manuals to find the answer to a technical question about some hardware, or summarize years of bank and credit card statements.
Retrieval-augmented generation, or RAG, is one of the easiest and most effective ways to hone LLMs for a particular dataset.
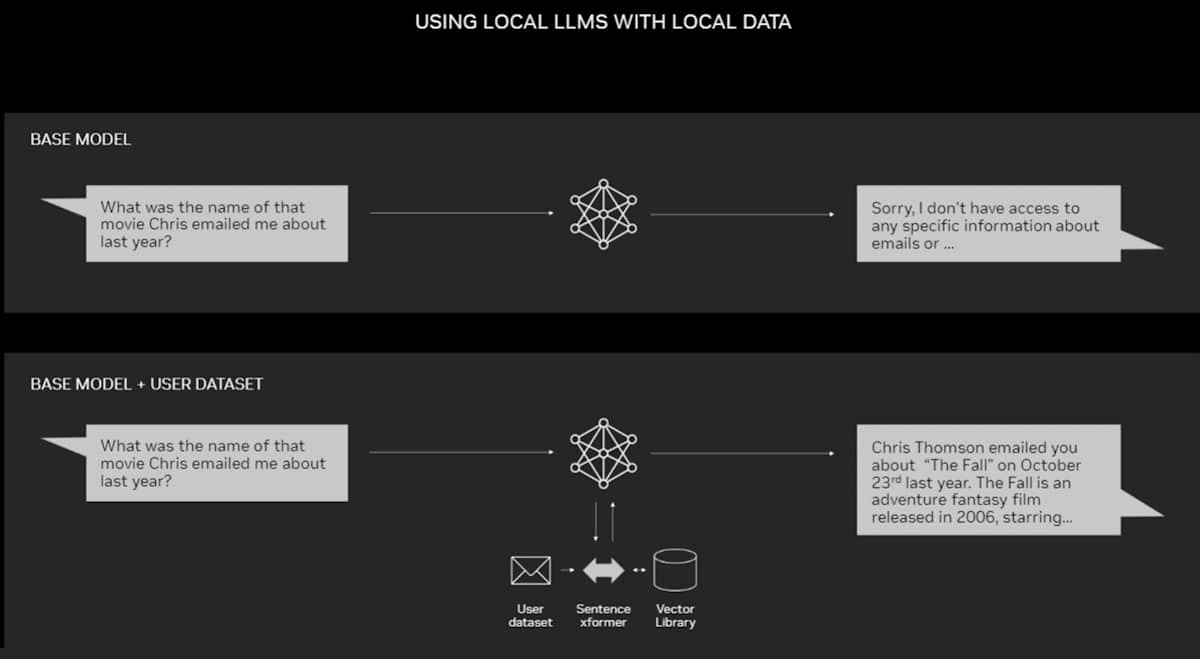
RAG enhances the accuracy and reliability of generative AI models with facts fetched from external sources. By connecting an LLM with practically any external resource, RAG lets users chat with data repositories while also giving the LLM the ability to cite its sources. The user experience is as simple as pointing the chatbot toward a file or directory.
For example, a standard LLM will have general knowledge about content strategy best practices, marketing tactics and basic insights into a particular industry or customer base. But connecting it via RAG to marketing assets supporting a product launch would allow it to analyze the content and help plan a tailored strategy.
RAG works with any LLM, as the application supports it. NVIDIA’s Chat with RTX tech demo is an example of RAG connecting an LLM to a personal dataset. It runs locally on systems with a GeForce RTX or NVIDIA RTX professional GPU.
To learn more about RAG and how it compares to fine-tuning an LLM, read the tech blog, RAG 101: Retrieval-Augmented Generation Questions Answered.
Experience the Speed and Privacy of Chat with RTX
Chat with RTX is a local, personalized chatbot demo that’s easy to use and free to download. It’s built with RAG functionality and TensorRT-LLM and RTX acceleration. It supports multiple open-source LLMs, including Meta’s Llama 2 and Mistral’s Mistral. Support for Google’s Gemma is coming in a future update.
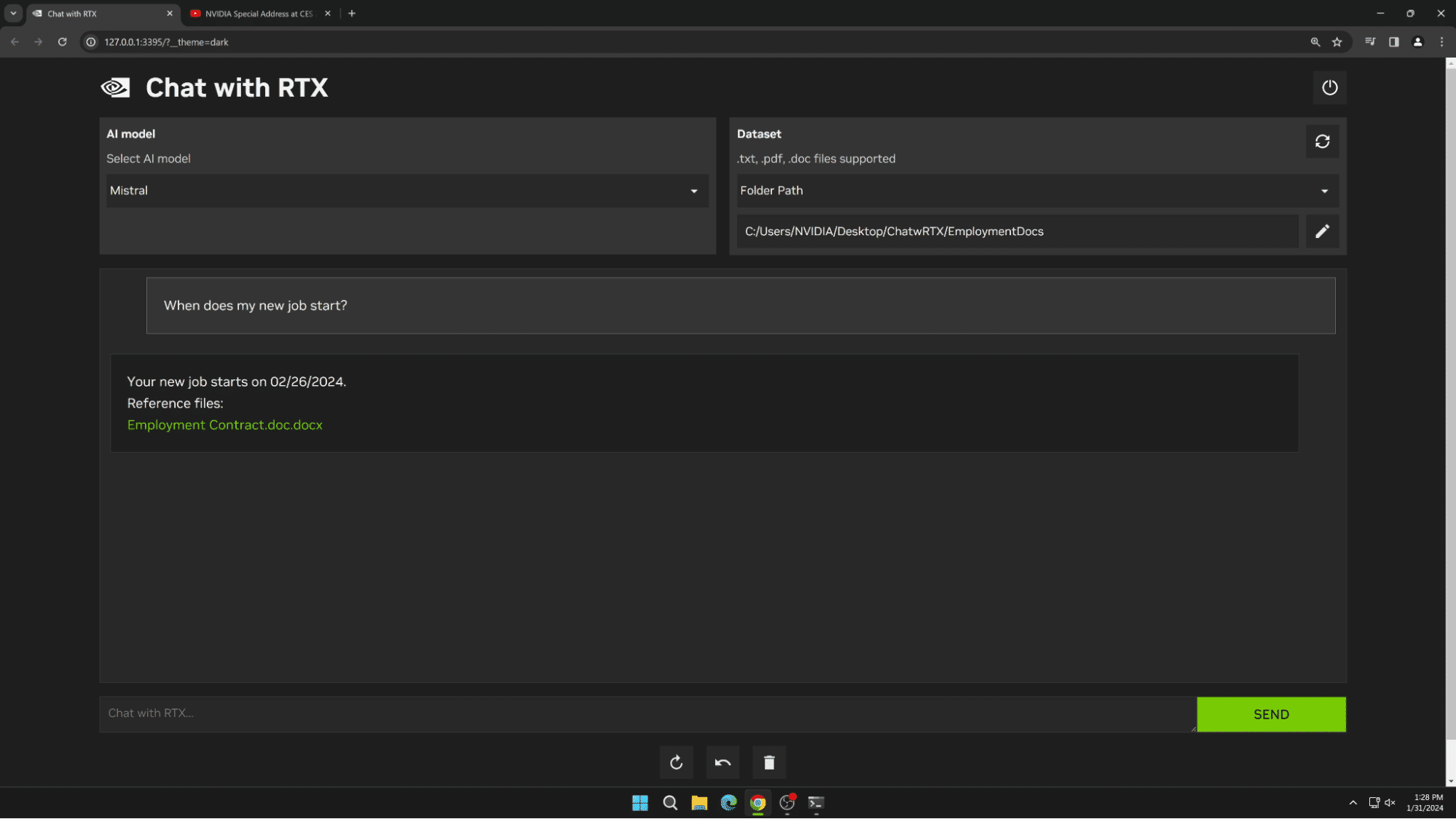
Users can easily connect local files on a PC to a supported LLM simply by dropping files into a folder and pointing the demo to that location. Doing so enables it to answer queries with quick, contextually relevant answers.
Since Chat with RTX runs locally on Windows with GeForce RTX PCs and NVIDIA RTX workstations, results are fast — and the user’s data stays on the device. Rather than relying on cloud-based services, Chat with RTX lets users process sensitive data on a local PC without the need to share it with a third party or have an internet connection.
To learn more about how AI is shaping the future, tune in to NVIDIA GTC, a global AI developer conference running March 18-21 in San Jose, Calif., and online.