Editor’s note: This is the latest post in our NVIDIA DRIVE Labs series. With this series, we’re taking an engineering-focused look at individual autonomous vehicle challenges and how the NVIDIA DRIVE AV Software team is mastering them. Catch up on our earlier posts, here.
MISSION: Predicting the Future Motion of Objects
APPROACH: Recurrent Neural Networks (RNNs)
From distracted drivers crossing over lanes to pedestrians darting out from between parked cars, driving can be unpredictable. Such unexpected maneuvers mean drivers have to plan for different futures while behind the wheel.
If we could accurately predict whether a car will move in front of ours or if a pedestrian will cross the street, we could make optimal planning decisions for our own actions.
Autonomous vehicles face the same challenge, and use computational methods and sensor data, such as a sequence of images, to figure out how an object is moving in time. Such temporal information can be used by the self-driving car to correctly anticipate future actions of surrounding traffic and adjust its trajectory as needed.
The key is to analyze temporal information in an image sequence in a way that generates accurate future motion predictions despite the presence of uncertainty and unpredictability.
To perform this analysis, we use a member of the sequential deep neural network family known as recurrent neural networks (RNNs).
What Is an RNN?
Typical convolutional neural networks (CNNs) process information in a given image frame independently of what they have learned from previous frames. However, RNN structure supports memory, such that it can leverage past insights when computing future predictions.
RNNs, thus, feature a natural way to take in a temporal sequence of images (that is, video) and produce state-of-the-art temporal prediction results.
With their capacity to learn from large amounts of temporal data, RNNs have important advantages. Since they don’t have to only rely on local, frame-by-frame, pixel-based changes in an image, they increase prediction robustness for motion of non-rigid objects, like pedestrians and animals.
RNNs also enable the use of contextual information, such as how a given object appears to be moving relative to its static surroundings, when predicting its future motion (that is, its future position and velocity).
Using Cross-Sensor Data to Train RNNs
Radar and lidar sensors are very good at measuring object velocity. Consequently, in our approach, we use data from both to generate ground truth information to train the RNN to predict object velocity rather than seeking to extract this information from human-labeled camera images.
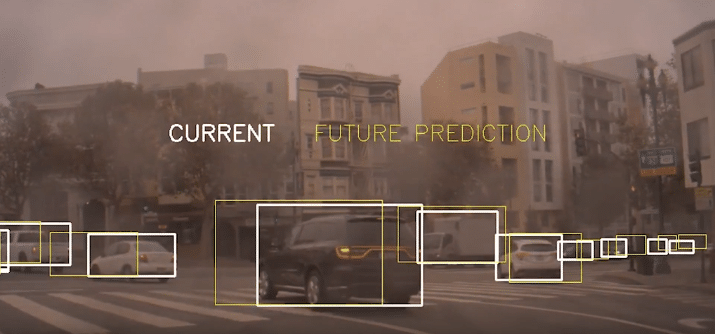
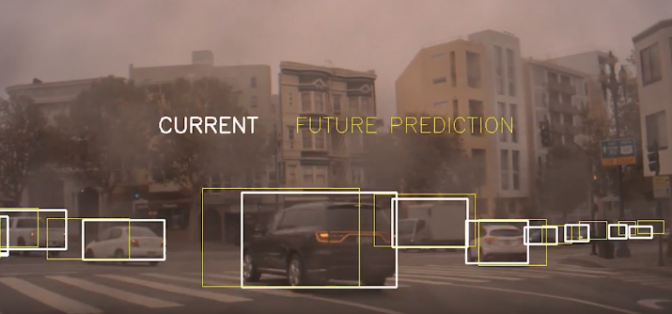
Specifically, we propagate the lidar and radar information into the camera domain to label camera images with velocity data. This lets us exploit cross-sensor fusion to create an automated data pipeline that generates ground truth information for RNN training.
The RNN output consists of time-to-collision (TTC), future position and future velocity predictions for each dynamic object detected in the scene (for example, cars and pedestrians). These results can provide essential input information to longitudinal control functions in an autonomous vehicle, such as automatic cruise control and automatic emergency braking.
With RNNs’ ability to learn from the past, we’re able to create a safer future for autonomous vehicles.