
Written by Emmanuel Turlay in collaboration with James Luo, Guozhen La, Brian Calvert, Jai Chopra, Lei Xu and Markus Mar-Liu.
In modern companies, data is the basis that many products and decisions are made on. As a Machine Learning-first company, Cruise is no exception in that regard.
Cruise has petabytes of heterogeneous data: time series of sensor readings, human-labeled data, images, videos, audio clips, relational data from operational stores, 3D LiDAR point clouds, rasterized and vectorized maps, ML predictions, external datasets, and more. All of these data types need to be readily accessible and highly available for any engineer to develop data pipelines for analysis, ML, etc.
It is neither realistic nor scalable to expect every Cruise engineer to know how to retrieve data, obtain credentials and access, parallel-process, and reference these data multitudes. To solve this, we developed Terra, an extension of the Apache Beam SDK that:
- Reduces friction to access Cruise data
- Abstracts away Cruise infrastructure and permissions
- Standardizes storage and development at Cruise
Terra conceals the infrastructural support previously implemented by each user around dataset registration, lineage tracking, timestamp synchronization, windowing, automatic schema inference, data validation, feature discovery, and more. This allows the user to concentrate on data feature extraction.
Every week at Cruise, over 70 unique users submit over 2000 jobs using Terra. So far, Terra has improved feature engineering pipelines runtime by up to two orders of magnitude and increased engineering productivity by reducing turnaround time and promoting modularity and reuse of code across teams.
With Terra, new hires can write a pipeline that generates millions of rows of complex feature data in a matter of hours.
How Terra was created
Terra was designed and built in Python on top of Apache Beam, a flexible DSL for defining data processing pipelines. Beam makes it extremely easy to define complex DAGs (Directed Acyclic Graphs) of data-processing steps including branching, joining, mapping (N → N), reducing (N → n, n < N), fanning out (n → N, n < N), and reading and writing datasets to/from files or popular databases and warehouses. It supports both batch (all at once) and stream (as they come) execution modes, including complex windowing capabilities.
Apache Beam is the de-facto way to define pipelines to be executed on Google Dataflow. It also supports other backends, such as Apache Spark and Apache Flink through open-source contributions.
To streamline end-to-end user workflows, Terra provides programming simplicity to users:
- Permission management
- Environment packaging and job submission
- Integration with Cruise data stores
- Boilerplate Transforms
- Lineage of Jobs and Datasets
- Interactive Data Processing
Permission management
Once a user is authenticated with our central secrets vault, Terra manages the service accounts required to submit jobs to remote compute clusters, and the coordination of lineage traceability with our Lineage and Feature Stores.
Environment packaging and job submission
Dependency management is one of the hardest problems when processing data at scale on highly-parallelized clusters. Users’ diverse local dependencies (public packages, private Cruise Python packages, native C++ libraries, etc.) need to be resolved, packaged, and shipped to workers and installed in a high-fidelity manner in order to reproduce the expected compute environment. Some pipelines even involve recreating on remote workers the run-time environment found on our autonomous vehicle in order to re-execute particular versions of the car stack.
Terra neatly abstracts dependency management in order to empower users to build these complex pipelines without a deep expertise of environment deployment.
Integration with Cruise data stores
Numerous data sources (raw car data, labeled data, map data, operational data) are available in various stores with different access patterns (warehoused, behind an API, in an online database, in cloud file-systems) and scalabilities.
In order to enable easy access, Terra provides standard connectors to each of these different stores that are designed to be intuitive to users instead of the system semantics of these data stores.
Boilerplate transforms for common operations
Instead of every engineer wasting precious time redefining basic data manipulation operations, each potentially in different sub-optimal ways, Terra provides centralized, optimized boilerplate operations that are peer-reviewed by platform engineers and constantly kept updated for all users.
These operations include basic I/O tasks (reading/writing to/from local or remote files and stores), dataset splitting logic, data manipulation (manipulating fields, converting types, reading complex serializations), additional common map/reduce operations (group by key, join, etc.), debugging tools, fault tolerance handling, and so on.
For example, fan-out operations often require reshuffling the data across workers to maximize parallelization. When developers use these operations, Terra automatically optimizes parallelization.
Here is how a typical Terra pipeline might look:
import apache_beam as beam
from terra.beam import Pipeline, TolerantParDo, FetchImage
from terra.beam.io import ReadFromBigQuery, WriteToFeatureStore, FetchCarData
with Pipeline(...) as pipeline:
pcoll = (
pipeline
| "Query Data Lake" >> ReadFromBigQuery(query=SQL_QUERY)
| "Filter invalid data" >> beam.Filter(my_filter_fn)
| "Fetch labeled image" >> FetchImage(
url_field="image_url", field="image")
| "Retrieve sensor data" >> FetchCarData()
| "Extract features" >> TolerantParDo(
FeatureExtractionDoFn(), tolerance=0.01)
| "Store features" >> WriteToFeatureStore()
)
Lineage and traceability of data
A critical part of ML workflows is traceability and lineage. To enable this in our data processing jobs, Terra is natively integrated with Cruise’s ML metadata and lineage store.
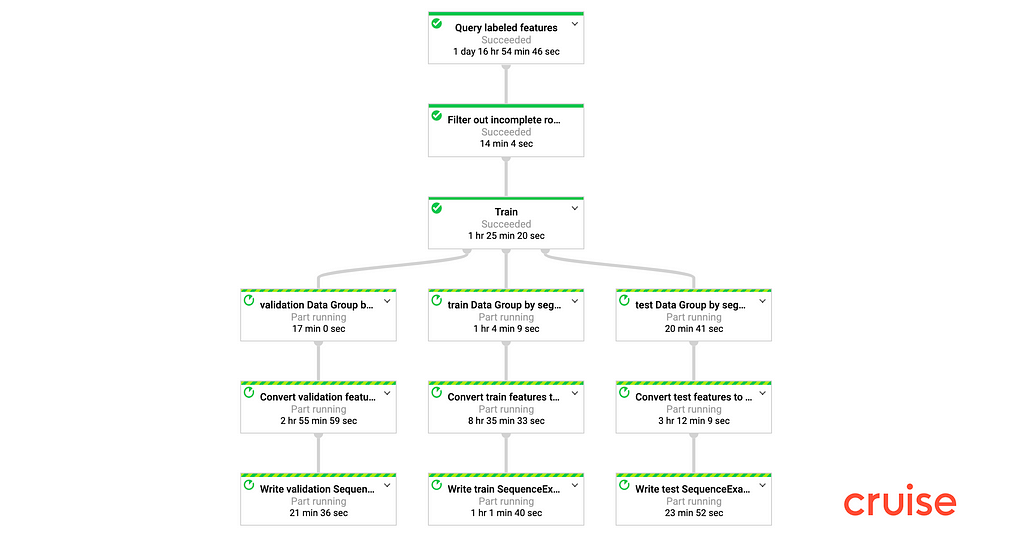
Upon job submission, Terra will inspect the DAG and extract relevant information (transform names, parameters, SQL query strings, compute configurations, output artifact specifications, etc.) and persist it in a data store fronted by a web UI.
Interactive data processing
For pipeline development work inside Jupyter Notebooks, users need to quickly iterate over changes and be able to re-execute parts of a pipeline to update visualizations.
Terra works inside notebooks and even lets users process large data chunks on remote Spark cluster for even faster turnaround times.
Almost a year after the release of its initial versions, Terra has become the entry point for Cruisers to iterate on their data-processing needs at scale. It is also the underlying framework powering large-scale automated production pipelines for mission-critical models.
Generating the training dataset for a key vision-based ML model went from 2 days to 20 minutes by adopting Terra. Similarly, the pipeline for a statistical model around critical on-road events extracted 68GB of features from 390,000 road segments in under an hour using Terra.
Join us
Interested in using machine learning in new and exciting ways? Join us and work on our unique engineering challenges.
Introducing Terra, Cruise’s Data Processing Platform was originally published in Cruise on Medium, where people are continuing the conversation by highlighting and responding to this story.