
By: Interns Eric Vincent¹ and Kanaad Parvate², with support from Andrew Zhong, Lars Schnyder, Kiril Vidimce, Lei Zhang, and Ashesh Jain from our Perception Team
Accurate perception to enable safe autonomy
In order to safely navigate the world, an autonomous vehicle (AV) needs to accurately perceive the objects that surround it. This includes dynamic objects such as cars, pedestrians, and cyclists, as well as static entities such as debris on the road, construction cones, traffic lights, and traffic signs. Perception software also needs to operate in real-time and with high fidelity: It demands both high precision (no false detection) and high recall (never missing an obstacle on the road).
To achieve high reliability, our AVs depend on three complementary sensing modalities: lidar, radar, and camera. They also depend on modern compute (such as GPUs) to process data from these sensors in real time.
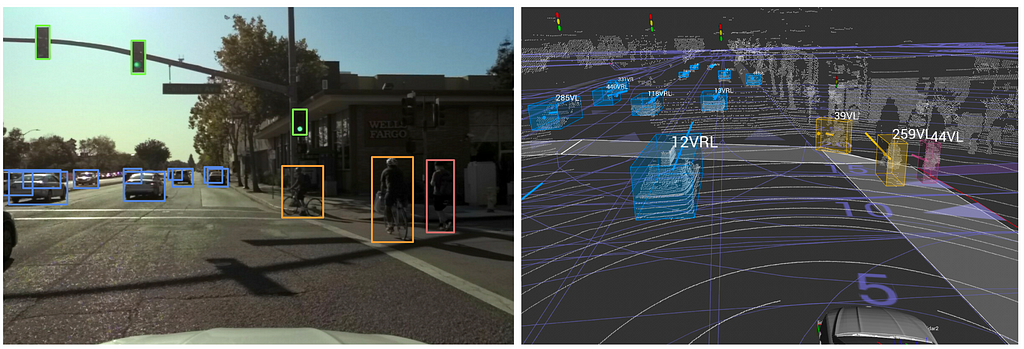
The perception software is responsible for fusing all sensing modalities to achieve an accurate 3D representation of the world. The output of the perception software consists of precise 3D positions of all the objects, their velocities, accelerations, and semantics, including object type labels (car, pedestrians, cyclists, etc.).
We design this software to leverage the sensors’ complementary strengths. For example, lidar provides very accurate depth, but doesn’t provide color information (so it can’t tell when a light is green or red). Cameras can fill this gap by providing color information, but don’t capture an object’s depth (so it can be challenging to localize objects). Radar provides direct velocity measurements of the objects — complementing both lidar and cameras. Core to the problem of perception is solving how to fuse these different sensing modalities.
Paradigms of sensor fusion
The goal of sensor fusion is to leverage the complementary strengths of the sensing modalities while canceling out their weaknesses. With recent advances in deep learning, two paradigms of sensor fusion have emerged. Late fusion processes each sensing modality independently until the very end, using probabilistic techniques to fuse them in the final stages [1]. Early fusion leverages recent advances in deep learning [2–7], using neural networks to fuse the raw sensor reading in the early stages.
Late Fusion
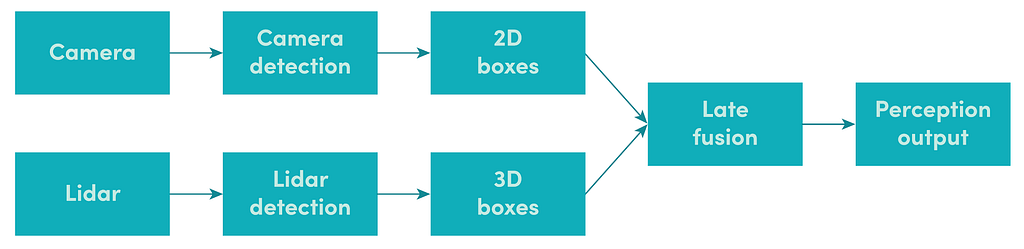
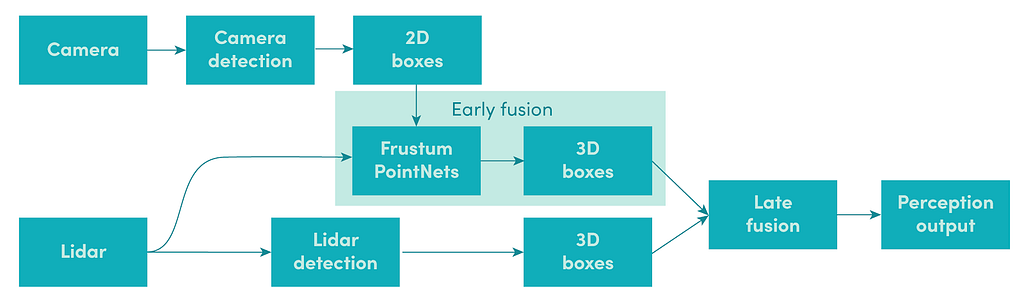
Late fusion provides much-needed interpretability in the perception software. It allows engineers to inject their prior knowledge about the world, such as the physical constraints on how a car can move. Probabilistic reasoning using methods such as Kalman Filters [1] also provides a principled way to reason about uncertainties in perception. For example, in a late fusion pipeline, objects may first be detected as 3D bounding boxes in a lidar point cloud and 2D bounding boxes in camera images. Then the association between the 2D and 3D boxes can be determined later in the pipeline (as shown in the image below). With this approach, a lidar data processing algorithm may be designed to rely on geometric clustering to extract all possible objects in the scene (high recall).
Early fusion
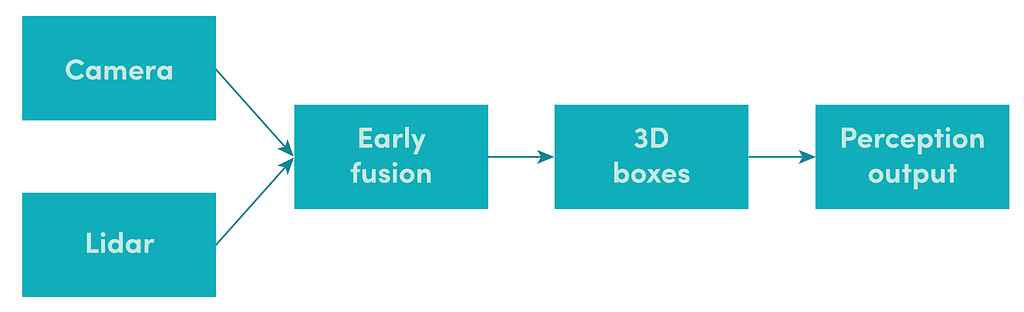
Early fusion harnesses the power of deep learning to learn and infer from multiple sensor modalities at the same time. With early fusion, the neural networks take raw sensor observations as input and learn the complementary strengths and weaknesses of the modalities. The final result is often better than what can be achieved with a single modality alone [4].
Establishing a baseline using late fusion
Both late and early fusion have their advantages. In our perspective, they complement each other, and we use both to achieve high fidelity and redundancy in our perception software.
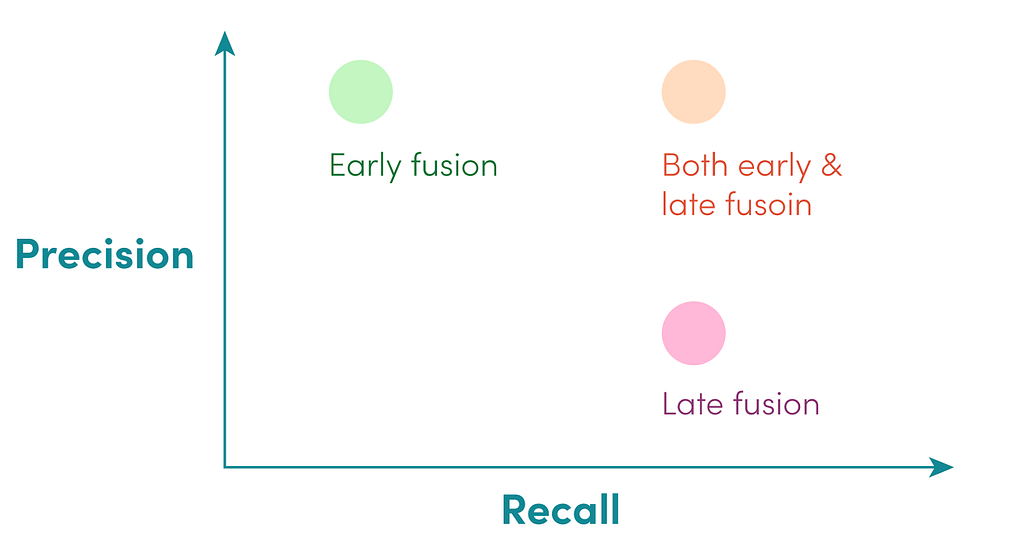
Since late fusion gives us interpretability and an ability to inject priors, we use it to build a baseline perception system with high recall (i.e. never missing an obstacle), potentially improving safety. It can allow us to divide and conquer the perception challenge by each sensor modality, and establish an end-to-end baseline that we can improve upon with early fusion.
The late fusion pipeline we built consists of a data-processing pipeline for each of the sensor modalities (lidar, radar, and camera) and a fusion step at the very end. For this blog post, we’ll describe potential lidar and camera pipelines.
To detect objects in lidar point clouds, we group points that are close together into clusters and fit each cluster into a 3D bounding box. This simple geometric clustering algorithm provides a strong guarantee that no objects — like debris or bushes — are missed. To complement this, we can add a deep-learned 3D detector in the lidar pipeline to improve the detection accuracy of a finite number of classes of objects, such as pedestrians, cyclists, and cars. To detect objects in camera images, we use a deep-learned 2D detector trained to identify pedestrians, cyclists, cars, and other objects.
We then decide if the detections from the two modalities belong to the same physical objects according to a set of geometric, physical, and semantic matching constraints in a step called data association. Finally, we rely on probabilistic methods to maintain a coherent understanding of the objects over time.
Boosting perception software with early fusion
The late fusion perception pipeline gives us a high-recall baseline. To further boost the performance of perception, we rely on passing higher quality inputs into late fusion. For example, by providing a more accurate 3D detections to late fusion, we can increase the precision with which we detect obstacles. This is where recent advances in early fusion help.
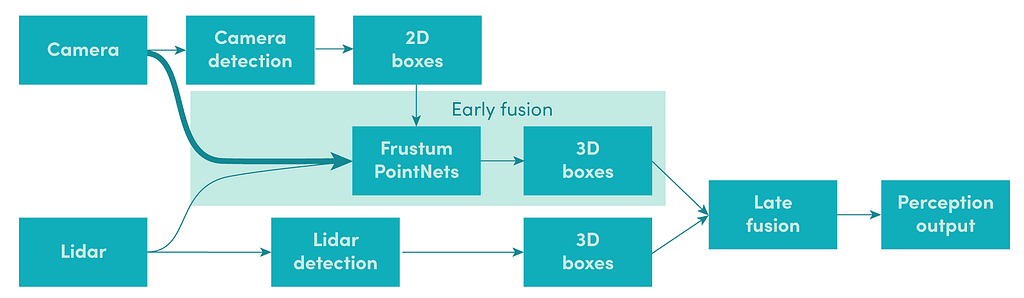
Early fusion models that directly extract information from multiple modalities of data are chosen to complement and enhance the late fusion pipeline. We initially explored Frustum PointNets architecture [2], which first selects all the lidar points that are inside the camera frustum of each 2D bounding box. It then predicts a 3D bounding box using a PointNet-based model that operates on the points within each frustum.
This early fusion model greatly improves perception software. However, more benefits can be unlocked in two ways: by continuously improving the early fusion model itself, and by utilizing the results of early fusion in more parts of the pipeline.
Improving the early fusion model
One of the initial Frustum PointNets models we explored took the raw lidar points, camera 2D detection bounding boxes, and class labels as the inputs. It didn’t have access to the raw camera image, which contains rich semantic information beyond just the bounding box coordinates and class label. This model could be improved by adding raw camera data as an additional input to the Frustum PointNets to make fusion occur even earlier.
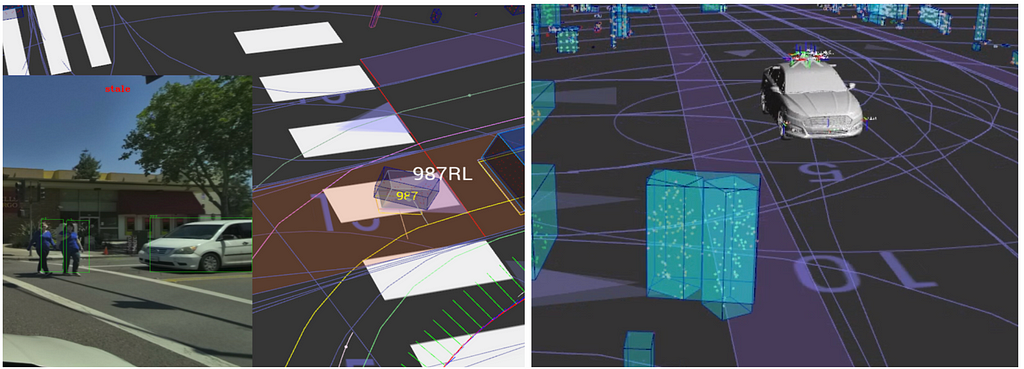
The benefit of adding raw camera data to the model input is evident in the following common use case. When a vehicle is far away from the self-driving car or is heavily occluded (either by other objects or truncated by the camera borders), the points are sparse or ambiguous enough that they alone can’t provide enough information to predict the full 3D bounding box of the vehicle. Even for a human, it would be difficult to distinguish between the back and front of the vehicle using lidar points alone — but the densely colored camera image gives us a good estimation of the size and orientation of the vehicle.

An approach similar to the PointFusion architecture [3] can be used to fuse the raw camera image into Frustum PointNets. This is done by first extracting useful features from this input image using a ResNet backbone [8], then by fusing the vision features in multiple stages of the Frustum PointNets architecture. In this design, each stage in the Frustum PointNets architecture has a semantic representation of both the point cloud and the image to use when computing its output. Vision features allow more accurate predictions in formerly ambiguous cases of using point features alone. The vision feature extraction network is trained end-to-end with the rest of the Frustum PointNets model.
This additional input of camera data can help our Frustum PointNets detect objects more accurately. Errors in the heading angle of the output bounding boxes were reduced significantly, and qualitative analysis confirms that the cases with the best improvement often had very sparse points but clear images.
Improving lidar processing with early fusion
We benefit further from early fusion by using its output in more parts of the perception software. One such place is the lidar geometric clustering step, which groups points together based on their proximity from each other (it assumes that points which are close together belong to the same physical object). Simply using the lidar geometry may not be ideal in crowded scenes. For example, two pedestrians that are close together may get clustered together into one. We call this under-segmentation, and it makes downstream late fusion difficult.
To improve the lidar clustering algorithm, we can augment each lidar point with additional information (e.g. a class label) and use this additional information to do better clustering. The 3D bounding box outputs from the early fusion model (Frustum PointNets) can be used to label the lidar points with the instance ID and a specific class type (e.g. car, pedestrian, cyclist). This provides additional clues to the lidar clustering algorithm so it can avoid grouping points associated with different objects into a single cluster.
Future work
Early and late fusion are two complementary sensor fusion paradigms. In the foreseeable future, we will continue using both in our perception software to achieve high fidelity and redundancy. Meanwhile, there are also unique challenges associated with early fusion. For example, early fusion models are likely to consume more compute resources than single-modality models. Additionally, early fusion models are more sensitive to the availability of the data of all modalities compared to single-modality models. For example, since lidar is unaffected by the lighting conditions, a lidar-only model can work equally well both day and night. But a lidar-camera fused model may need more training data to operate 24 hours a day. All these aspects need to be carefully considered when integrating early fusion in our perception software.
We are actively seeking talented students, engineers and researchers to help us solve these challenges. Explore our University Programs and Level 5 open roles to learn more.
About the interns
- Eric Vincent is currently a senior at Stanford where he is pursuing a B.S. in Computer Science. He was part of the Level 5 summer intern program in 2019. His intern project focused on enhancing our lidar-camera early fusion model for 3D object detection.
- Kanaad Parvate is currently pursuing an M.S. in EECS at UC Berkeley. He was also part of the Level 5 summer intern program in 2019. His intern project focused on improving lidar processing using semantic information from early fusion.
References
[1] Thrun, Sebastian, Wolfram Burgard, and Dieter Fox. Probabilistic robotics. MIT press, 2005.
Leveraging Early Sensor Fusion for Safer Autonomous Vehicles was originally published in Lyft Level 5 on Medium, where people are continuing the conversation by highlighting and responding to this story.