By: Emil Praun, Principal Engineer and Michael Benisch, Engineering Director

A common challenge when deciding which autonomous problems to solve first is how to balance breadth versus depth. Going broad means expanding the Operational Design Domain (ODD) of situations that an autonomous vehicle (AV) can handle. Example situations include operating on highways and city streets, at night, in the rain, in congested areas, around pedestrians, and around cyclists. Going deep means mastering a specific, narrow ODD to the point of being able to operate reliably and repeatedly without human intervention or supervision.
Both breadth and depth must be solved for to create a sustainable AV program. The question that remains is whether to sequence or balance the two. It is possible to take the common approach of starting with the question that has the most unknowns, as its answers could significantly impact the solutions for the remaining questions.
According to this approach, it makes sense to address depth first since it’s considered more unknown in the AV industry. However, focusing too narrowly on depth could lead to building a demo without the technology or learnings to solve the larger problem. It’s critical to solve for depth while using an approach that can generalize well to optimize the time it takes to reach the full solution.
What does it mean to generalize?
Generalizing in the context of AVs means that the solution for a given ODD should require minor work to achieve the same level of safety and reliability in a slightly expanded ODD. For example, say it takes two years to go from operating only in sunny weather to include operating in fog. The processes and technology developed for this ODD should make it possible to operate in rain, sleet, or snow in only a comparatively shorter time.
The development velocity that follows clearing major milestones is a good indicator of a solution’s generalization power. The progress in key metrics, such as Miles Per Intervention (MPI), is typically steeper just before achieving major milestones. There shouldn’t be a significant dip in development velocity after clearing a major milestone and aligning towards the next one. You want to reach milestones with a strong “exit velocity” and maintain a consistent development speed over a long period.
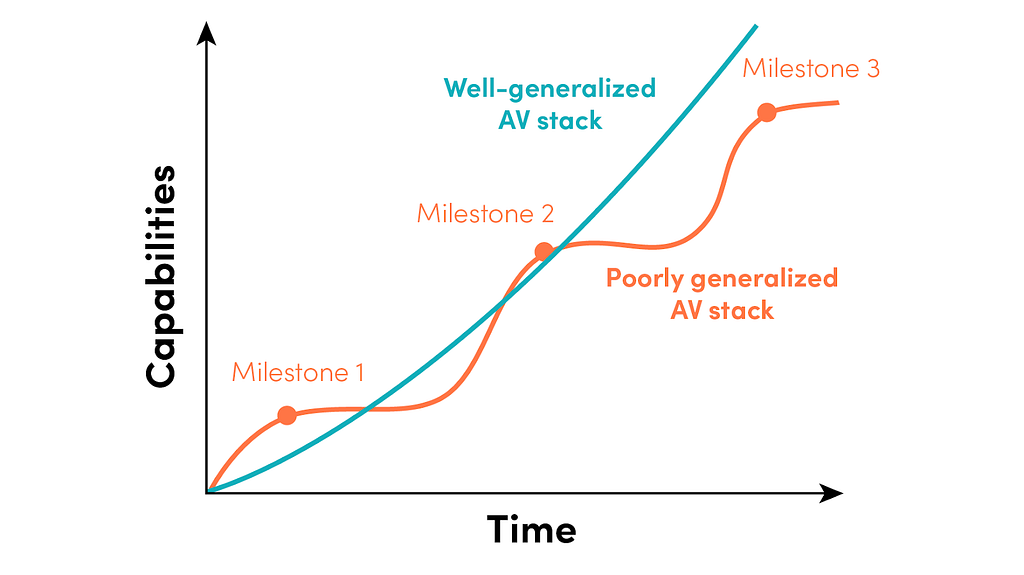
Why generalization power is important
There are understandable reasons not to develop solutions that are too general too early. For example, it could reduce short-term velocity and have a detrimental impact on the program as a whole. However, balancing an appropriate investment in generalization should lead to a more successful AV strategy for the long run, including:
- Higher probability of long-term success
This is one of the main benefits. To be successful, an AV program must reach an ODD broad enough to be economically viable. So, a strategy that includes generalization carries less risk than one that completely ignores it (even early on). - Higher longer-term development velocity
There are plenty of overfit solutions that allow fully driverless capabilities in a very narrow ODD, but are dead-ends when it comes to expanding the ODD. It may be possible to intuitively avoid most dead-end solutions, but more nuanced tradeoffs quickly become difficult to solve. A well-generalized AV stack dodges this pitfall and shortens the time to achieve a business-viable goal. - Lower resource cost
A less-obvious benefit of developing with generalization is that it can help reduce the resources needed to get to a viable goal. By definition, a system that generalizes well requires less effort to maintain and extend to meet new needs. As a result, there is less of a tax for dealing with legacy software and hardware. - More stimulating work
As an added bonus, most engineers find developing more general solutions intellectually stimulating. This approach is therefore beneficial to long-term organization health.
Developing for generalization
While it is an added step, generalization is worth prioritizing given its impact on long-term success. We’ve found these tactics useful for encouraging well-generalized stacks.
- Set goals. This is one of the most powerful mechanisms for executing on generalization. When planning development milestones, include not only the main performance goal for the milestone’s ODD, but also a lower-performance goal for an expanded ODD. Even if this secondary goal isn’t achieved, articulating it and measuring system performance against it steers development towards solutions with better generalization.
This is similar to how we typically use a separate validation dataset to avoid overfitting when developing machine learning or artificial intelligence systems. - Track generalization debt. If setting a secondary generalization goal isn’t practical due to concerns over diluting focus or clarity of goals, it is also possible to track the “generalization debt” of a solution. One way to operationalize this is to note (in a work-tracking system) the additional effort needed to solve a problem or implement a feature in the context of the next relevant ODD. The process should identify the debt tickets, update them to refer to the next ODD, and allocate time and resources to fix the tickets and reclaim the debt.
- Trade off the right amount of feature velocity. Generalization aligns well with traditional software development practices for maintainability and reuse. So, a good way to increase generalization power is to balance the right amount of feature velocity with an emphasis on generalization practices. Too much focus on vertical feature development can result in specific feature assumptions permeating many layers of the code. Alternatively, well-structured code with well-encapsulated functional units can be re-assembled to support new or modified use cases. This approach also provides good test coverage, which protects against breakages when performing wide-reaching refactorings, rollouts of new hardware, or revising assumptions.
- Favor data-driven, generic machine learning approaches. These generalize better than handcrafted rules-based code and custom feature engineering for machine learning models. We can increase generalization power in machine learning frameworks by including data from neighboring ODDs in the test and validation sets. While it takes some work to tune an existing machine learning system after re-training on new datasets, it’s typically easier than adapting a rules-based system to a new ODD. Rules-based systems (“expert systems”) also tend to become brittle with complexity. They can be valuable when advising humans in situations like medical diagnostics or Level 3-assisted driving, but it is challenging to get them to perform at the level required to function without human input.
Tracking generalization ability
Use a feedback loop for development processes to determine whether the approach is effective. For generalization, development velocity metrics and simulation validity metrics can ensure the project is going in the right direction.
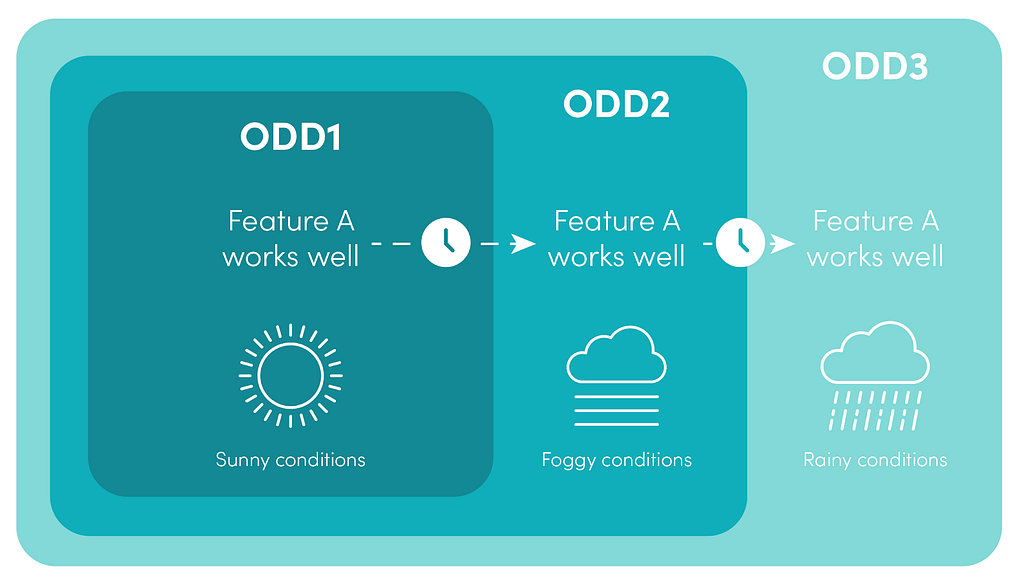
Development velocity metrics
Long-term velocity metrics include tracking the following against ODD changes:
- The time to develop new features
- The time to reach parity in performance for existing features on new routes and with new hardware.
For example, it is possible to develop a feature on an initial restricted ODD1, then get it to perform comparably for an expanded ODD2, then for an even further expanded ODD3. This porting effort should be small and the work required to move to ODD3 should be smaller than what was needed to move to ODD2. In addition to these feature-based metrics, it is possible to observe changes in standard metrics for different ODDs such as time to release, time to triage, and build times.
Simulation validity metrics
Simulation is a powerful tool for assessing generalization, which generally can be done at a lower cost than physically driving a countless miles in varied conditions and locations. However, the results obtained in simulation are most useful when they reflect what happens in the real world. We can ensure that this is the case by tracking metrics that continuously compare the expected behavior in a simulation to actual real-world data (in locations where the data is available). The need for continuous validation precludes relying exclusively on simulation as a substitute to physical driving.
To gather the metrics above, you can borrow an approach developed to address overfitting and generalization for generic machine learning: separation of data into training, test, and validation sets. These concepts can be directly applied to physical ODDs. Validate new areas, move to test, and finally train as features become part of the committed ODD.
Conclusion
In the autonomous industry, exploring depth first gives the benefit of uncovering the most unknowns and applying learnings to remaining breadth questions. However, an AV program must reach an ODD broad enough to be economically viable. That being said, prioritizing depth exploration while measuring generalization power and biasing towards solutions that generalize well leads to the most promising AV development strategy.
This approach can be applied to building any complex, machine-learning-heavy stack. To put this into practice, start by setting organizational goals that encourage generalization. From there, engineers can use the methods outlined in this blog to incorporate, increase, and measure the generalization power in their development processes.
There are many ways to think about solving problems like this. If you find these types of challenges exciting, Level 5 is hiring. Check out our open roles, and be sure to follow our blog for more technical content.
Generalization in Autonomous Vehicle Development was originally published in Lyft Level 5 on Medium, where people are continuing the conversation by highlighting and responding to this story.