

The holy grail for many artificial intelligence (AI) startups is to easily obtain data, and then extract value from that data with minimal human intervention. Self-supervised learning is an innovative approach that uses visual signals or domain knowledge, intrinsically correlated to the image, as automatic sources of supervision, thus removing the need for humans to label data. Given the importance of data to AI in general, and to autonomous mobility specifically, it’s one of the areas we’re following closely at Toyota AI Ventures.
Before we dive into how self-supervised learning can be utilized in the race to Level 5 (L5) autonomy, let’s take a look at the big picture and some of the major challenges involved in big data and AI.
Enter Machine Learning (ML).
The point of ML is to give machines superhuman capabilities by using data to generate complex programs that learn from experience. Why? Because human intelligence does not scale fast enough. Efficiently utilizing ML in your software stack requires combining some “Newton” (prior knowledge about the physical world) with some “Hinton” (posterior knowledge acquisition from experience) by “engineering what you know and learning what you don’t.”
There is plenty of raw data, but extracting useful labels from that data is expensive. The two main types of ML tasks, supervised learning and unsupervised learning, offer different pros and cons, depending on the use case. In supervised learning, you start with a dataset of training examples with associated correct labels. Here’s a classic example: When learning to classify whether an email is spam, a supervised learning algorithm analyzes thousands of emails, along with labels that identify if each message is spam, or not. The algorithm will then learn the relationship between the emails, and whether they are labeled as spam, and apply that learned relationship to classify completely new emails (without labels) that the machine hasn’t seen before.
When it comes to object detection in autonomous driving, many researchers believe that brute-force supervised learning will not get us to L5 in our lifetimes. A 2016 report by RAND found that autonomous vehicles (AVs) would have to be driven billions of miles to demonstrate acceptable reliability. According to Toyota Research Institute’s CEO Gill Pratt, we need trillion-mile reliability. Based on the current trajectory, it would be decades before we get to the billions of miles needed. On top of that long time horizon, the costs associated with a human labeling the objects generated from those miles are extremely high (approximately $4-$8 per image of 1920×1080 density for semantic segmentation, depending on quality of service), and just don’t scale. In addition, no one has really figured out a strong supervised learning practice that can capture all of the edge cases in road conditions well enough. There has to be a better way.
So what about unsupervised learning? Unsupervised learning can refer to a number of different practices or forms of ML, but you’ll typically hear discussions around clustering (grouping data by similarity), dimensionality reduction (compressing the data while maintaining its structure and usefulness), and recommender systems (think Netflix recommending movies to a user based on another user who had similar tastes). Unsupervised learning is most commonly used to pre-process a dataset. This sort of data transformation-based learning is starting to be seen as the old-school way of utilizing unsupervised learning, and new forms are starting to emerge.
That’s where self-supervised learning comes in. It is a unique form of ML that is a variant of unsupervised learning. An example we’ve seen in a number of startups is the ability to predict the depth of a scene from a single image, by using prior knowledge about the geometry of scenes. They are essentially creating geometric rules that supervise the network automatically.
We’ve also seen a few startups that can predict future frames of video from past ones, by using prior knowledge about time and causal reasoning. Behind every two-dimensional (2D) image, there is a three-dimensional (3D) world that explains it. When the 3D world is compressed down to a single 2D image, a lot of data is lost, and the way that it is compressed is not random. If you can harness that relationship between the 3D world and its compression into 2D images, you can then work backwards and input an image that allows an AV to understand the 3D world.
Another unique self-supervised approach that some startups and OEMs have been testing is placing cameras in their cars and comparing the video footage to the driver’s interaction with each specific road condition. Essentially, every time a driver is on the road, he or she is labeling driving data for the company through natural/self-supervision — without the company having to pay a human to physically annotate what the driver’s reaction was to the road conditions. Also, the spatial/temporal coherence of videos has a lot of latent structure that could be explored. Toyota AI Ventures is very interested in meeting with startups that can think of innovative ways to label “open space” on the road by harnessing these natural behaviors of data. Supervised or not, it needs to scale!
 Parallel Domain’s Virtual World Generation
Parallel Domain’s Virtual World Generation
Simulators are another way to solve the problem of expensive labeled data. Simulation can allow you to generate billions of miles of synthetic data that your ML models can learn from. However, the gap between synthetic and real datasets may lead a network trained on synthetic data to not work well enough in the real world. How can you learn to drive in a video game and then use that data effectively in the real world?
It’s common for startups and researchers to focus on photorealism by making simulators look more like the real world; however, increasing the realism is often computationally expensive and incredibly difficult for even the best renderers to model all characteristics of the real world. The paradigm that could help bridge this gap is domain adaptation, where you aim at learning a well-performing model from a source data distribution that differs, but is related to, a target data distribution. Virtual KITTI is an example of bridging the synthetic-to-real data gap by cloning the real-world in a virtual world through domain adaptation. Generative Adversarial Networks (GAN) are also a very promising and popular deep learning technique to learn how to efficiently make simulations look more realistic.
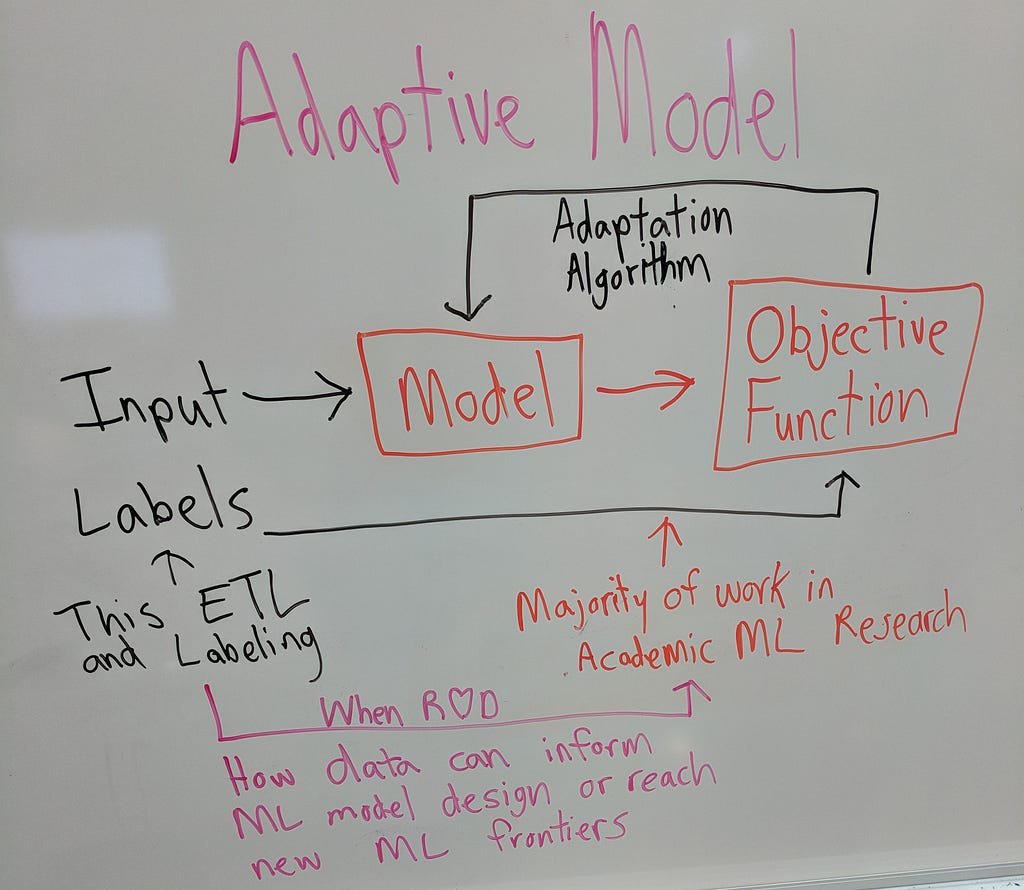 Courtesy of Toyota Research Institute
Courtesy of Toyota Research Institute
ML academic research is often centered around defining new model architectures and different ways to measure a model’s quality with objective functions (see the sketch above). ETL (Extract, Transform, Load) is a general term for data processing. Good supervised learning models are built by collecting inputs and their desired labels. The hard part is mining good data, which is often not the focus in a majority of ML academic research settings; however, when it is the focus, it can be very disruptive (cf. the ImageNet revolution).
We believe that great ML products involve knowledge of the full data supply chain. Understanding the latent structure of your data is key when mining, pre-processing, and ultimately designing new models and objective functions. Following this process could lead to discovering new ways to organically train ML models.
Think of data as the new gold and labeled data as the new jewelry — as investors, we are searching for great craftspeople. If you, or an entrepreneur you know, are building a unique learning solution that could be applied to the realm of autonomous mobility or robotics, we want to hear from you!
Contact Chris Abshire at chris(at)toyota-ai.ventures, or DM him on Twitter. Special thanks to Adrien Gaidon and Eder Santana for their insights and help putting this together.
Self-Supervised Learning: A Key to Unlocking Self-Driving Cars? was originally published in Toyota AI Ventures on Medium, where people are continuing the conversation by highlighting and responding to this story.