Twenty-eight years ago, Geoff Tate helped create a chip company called Rambus. Its technology is in every DRAM memory part that ships today. But Tate thinks he’s now found a bigger market in artificial intelligence and machine learning.
“I think neural networks is going to be a bigger market than what we did with Rambus,” said Tate, chief executive of startup Flex Logix, in an interview with ZDNet on the sidelines of the Linley Group Fall Processor Conference, hosted by venerable semiconductor analysis firm The Linley Group, in Santa Clara in Silicon Valley.
“Neural net chips are going to explode in both volume of chips produced and complexity,” Tate said. “If you were to make an analogy to the days of [Intel’s] x86, we are just at the stage of the 286 right now.”
Flex, founded four years ago and backed by venture firms Lux Capital and Eclipse Ventures, is going after the market known as “inferencing at the edge.” Inference is the part of machine learning when the neural net uses what it has learned during the training phase to deliver answers to new problems.
Also: AI Startup Cornami reveals details of neural net chip
The “edge,” in this case, refers to devices outside the data center, such as self-driving cars or IoT gadgets. Hence, inferencing at the edge might involve neural nets for things such as helping the car see the road or helping a connected camera identify people in crowds.

Flex Logix’s combines groups of mutliplier-accumulator circuits in banks of SRAM, with a special circuitry for connecting it all together called “XFLX.” The company claims this arrangement of parts will keep the processor busy more of the time with the data it needs, helping to vastly outperform Nvidia’s GPUs at inference of machine learning.
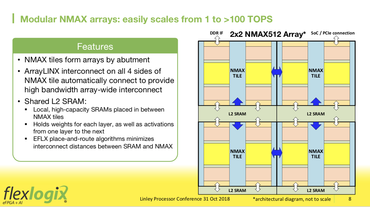
The company unveiled at the show its “NMAX” technology. This is based on what’s known as an “eFPGA,” a kind of programmable chip. The NMAX combines tons of identical compute elements, called multiplier-accumulators, that perform the matrix multiplications that are the fundamental task in neural networks. The multiplier-accumulators make up a “systolic array,” an old computer design that’s experiencing a revival as many chip makers use it for AI. (See the report last week on chip start-up Cornami.)
These groups of multiplier-accumulators are surrounded by SRAM memory circuits, and a high-speed interconnect called “XFLX” that connects the multiplier-accumulators to one another and to the SRAM. The SRAM holds the “weights,” the numeric values that shape the neural network.
Tate emphasizes the XFLX interconnect as the key to the chip’s performance. By being able to efficiently move data in and out of the SRAM to the clusters of multiplier-accumulators, the entire chip can be more efficient. The multiplier-accumulators are kept busy by always having the data they need, and the chip can minimize, or even avoid altogether, the costly process of going off-chip to DRAM. “Cutting DRAM means cutting cost and power,” Tate said. A special compiler program is being developed by Flex that optimizes the data flow around the chip.
Tate, and his co-founder Cheng Wang, head of engineering, took aim at Nvidia’s graphics processing units, or GPUs, currently the dominant form of compute. They argue that GPUs, while better than CPUs, are grossly inefficient for processing neural networks.
“Most of the time an Nvidia MAC [multiplier-accumulator] is doing nothing, so they need four times as much hardware” to get the same results, Tate said.
Also: Google says ‘exponential’ growth of AI is changing nature of compute
Wang asserted in his formal presentation at the show that the NMAX chip has ten times the price/performance of Nvidia’s “Tesla T4” GPU. The XFLX interconnect, and the reconfigurable nature of the FPGA circuits, mean the NMAX is idle less of the time, and therefore has a higher “utilization.” Most AI chip companies, said Wang, have various claims about the “tera-operations per second,” or TOPS, they can perform, promising to deliver more and more.
But Wang said most customers are more concerned with actual throughput and latency they can achieve. Higher utilization should produce more in the way of actual throughput whatever the raw TOPS count is.
On the benchmark “ResNet-50” neural network for image recognition, Wang said the NMAX can achieve an “efficiency” of its multiplier-accumulators of 87 percent, compared to less than 25 percent for the Tesla T4 and other kinds of chips.

Flex Logix boasts of better efficiency in its chips on benchmark tests involving certain machine learning neural nets such as “ResNet-50.”
“In our customer meetings, they have already benchmarked all this, and they know the issues of real versus promised performance,” Tate said. “We talked to one company that said the issue wasn’t how many TOPS can you do, it was how many can you do with one watt” of power. That’s because edge devices may be constrained by battery life, unlike servers sitting in a data center.
“We haven’t seen anything to match our capability,” Tate said. “And actually ResNet-50 is even a little misleading, because in the real world, as opposed to academic presentations, the neural networks are going to be much bigger than ResNet-50, and those networks will really tax the hardware.”
NMAX will be sold to customers as what’s called an “IP core,” a circuit design that they can incorporate into their own chips. Parts are expected to “tape out,” meaning, they’ll be available to customers, in the latter half of next year.
Previous and related coverage:
What is AI? Everything you need to know
An executive guide to artificial intelligence, from machine learning and general AI to neural networks.
What is deep learning? Everything you need to know
The lowdown on deep learning: from how it relates to the wider field of machine learning through to how to get started with it.
What is machine learning? Everything you need to know
This guide explains what machine learning is, how it is related to artificial intelligence, how it works and why it matters.
What is cloud computing? Everything you need to know about
An introduction to cloud computing right from the basics up to IaaS and PaaS, hybrid, public, and private cloud.