
Introducing Argoverse: data and HD maps for computer vision and machine learning research to advance self-driving technology
By James Hays, Principal Scientist, Argo AI
In today’s world of computer vision and machine learning research, it’s all about who has access to high-quality data — and how much of it. That’s because it takes a tremendous amount of data to train, validate, test and improve the perception algorithms and machine learning methods that enable self-driving vehicles to understand the world around them.
So today, Argo AI is excited to announce that we’re releasing high-quality, curated data and high-definition maps to the research community. Our data collection, Argoverse™, is the first public data release to include high-definition maps for self-driving vehicle research. Through Argoverse, academic researchers can explore the impact of HD maps on key perception and forecasting tasks, such as identifying and tracking objects on the road, and predicting where those objects will move seconds into the future.
Maps are critical to robotic perception tasks for all kinds of self-driving vehicles, from self-driving cars to self-driving floor scrubbers, shuttles, and even self-driving landmine detectors. Maps enable robots to correctly position themselves in the world and, when it comes to improving self-driving vehicle capabilities, maps are a key component of what enables experts to develop better prediction and tracking methods. This in turn helps to improve the way autonomous systems understand the world around them.
Despite the importance maps play in the advancement of self-driving technology, there are surprisingly few public datasets with detailed maps. That poses a challenge for university students, professors, and experts in the field who lack ties to companies with the resources to supply ample, relevant data through fleets of self-driving vehicles. The cost of public road testing is a clear factor: today it can cost upwards of a few hundred thousand dollars to produce a one-off prototype self-driving test vehicle. That is before the cost of building a map. So when we sat down to discuss Argoverse two years ago, we decided it was important to include geometric and semantic metadata, such as ground height, lane geometry and road segmentation.
For our team at Argo, releasing this data collection is about giving academic communities access to the materials they need. We’re excited to not only support cutting edge developments in computer vision and machine learning but also to support the next generation of engineers and roboticists who are preparing for jobs at self-driving technology companies, Argo AI included. We’ve long since supported the next generation of engineers through university partnerships, and have supported younger generations through educational programs and outreach efforts that get them excited about STEM career paths. Argoverse is an extension of that effort and a leap forward to support the continued advancement of this field.

Argo AI and Academic Research
Argo AI has a fleet of self-driving vehicles on the roads in five U.S. cities, including Miami and Pittsburgh, from which we’re sharing a subset of our data for Argoverse. This puts us in a position to make rich data available to the research community, free of charge under a creative commons share-alike license.
Data drives machine learning research, with researchers measuring progress by training and testing models on public datasets. Since 2012, research into self-driving perception tasks has been catalyzed by the KITTI dataset. Thousands of scientific papers use KITTI to benchmark algorithms for tasks such as 3D object detection. Argo and other companies oftentimes build on these algorithms from scientific literature to develop their own approaches.
Argoverse enables the research community to train and evaluate new map-aware approaches for these tasks to advance the capabilities of self-driving vehicles. It supports the public advancement of many of the same challenges that are being addressed by self-driving technology companies, Argo AI included.
Inside Argoverse: The Technical Details
Argoverse is a research collection with three distinct types of data. The first is a dataset with sensor data from 113 scenes observed by our fleet, with 3D tracking annotations on all objects. The second is a dataset of 300,000-plus scenarios observed by our fleet, wherein each scenario contains motion trajectories of all observed objects. The third is a set of HD maps of several neighborhoods in Pittsburgh and Miami, to add rich context for all of the data mentioned above.
Each of these elements is explained in detail below:
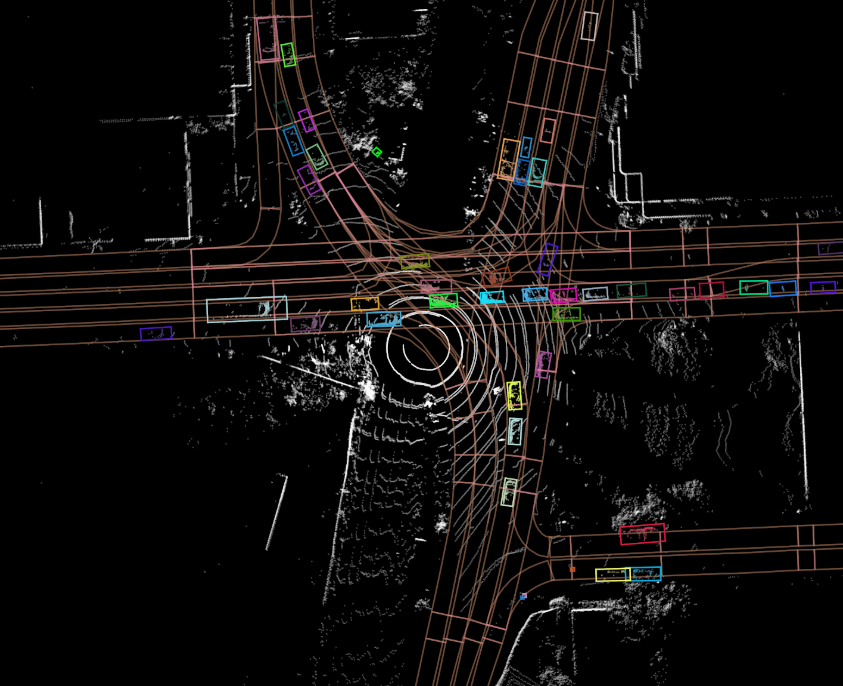
- Argoverse 3D tracking dataset. A core challenge for self-driving vehicles is knowing and understanding how other objects are moving in a surrounding scene. We call this task, “3D tracking.” Our 3D tracking dataset contains several types of sensor data: 30 frames per second (fps) video from seven cameras with a combined 360-degree field of view, forward-facing stereo imagery, 3D point clouds from long range LiDAR, and a 6-degree-of-freedom pose for the autonomous vehicle. We collect this sensor data for 113 scenes that vary in length from 15 to 30 seconds. For each scene, we annotate objects with 3D bounding cuboids. In total, the dataset contains more than 10,000 tracked objects.
- Argoverse motion forecasting dataset. For self-driving cars, it’s important to understand not just where objects have moved, which is the task of 3D tracking, but also where objects will move in the future. Like human drivers, self-driving cars need to assess, “Will that car merge into my lane?” and “Is this driver trying to turn left in front of me?” To build our motion forecasting dataset, we mined for interesting scenarios from more than 1,000 hours of fleet driving logs. “Interesting” means a vehicle is managing an intersection, slowing for a merging vehicle, accelerating after a turn, stopping for a pedestrian on the road, and more scenarios along these lines. We found more than 300,000 such scenarios. Each scenario contains the 2D, birds-eye-view centroid of each tracked object sampled at 10-hertz for five seconds. Each sequence has one interesting trajectory that is the focus of our forecasting benchmark. The challenge for an algorithm is to observe the first two seconds of the scenario and then predict the trajectory of a particular vehicle of interest for the next three seconds.
- Argoverse high-definition maps. Perhaps the most compelling aspect of Argoverse is our high-definition mapset containing 290 kilometers of mapped lanes. The maps contain not only the location of lanes, but also how they are connected for traffic flow. So when a lane enters an intersection, the map tells you which three successor lanes a driver might follow out of that intersection. The map has two other components as well: ground height and driveable area segmentation at 1m² resolution. Taken together, these maps make many perception tasks easier, including discarding uninteresting LiDAR returns using the ground height and driveable area features. It’s easier to forecast future driving trajectories by first inferring the lane that a driver is following. Vehicle orientation and velocity estimates can be refined by considering lane attributes like direction. No doubt countless other clever ways exist to incorporate these rich maps into self-driving perception tasks, but the academic community has not yet been able to explore this combination since no previous dataset has offered high-definition maps.
How can you use Argoverse?
You can download and learn more about the dataset at www.argoverse.org. We’ve also created an API to interact with the data and maps. If you’d like even more details, take a look at our research publication that will be presented at CVPR 2019. Argoverse is released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 license to allow public access and use.