
AI has many manifestations, ranging from hardware to applications in domains such as healthcare, and from futuristic models to ethics
metamorworks — Shutterstock
In the spirit of the last couple of years, we review developments in what we have identified as the key technology drivers for the 2020s in the world of databases, data management and AI. We are looking back at 2021, trying to identify patterns that will shape 2022.
Today we pick up from where we started with part one of our review, to cover AI and knowledge graphs.
The many faces of AI: Hardware, the edge, MLOps, language models, future architectures and ethics
special feature

Managing AI and ML in the Enterprise
The AI and ML deployments are well underway, but for CXOs the biggest issue will be managing these initiatives, and figuring out where the data science team fits in and what algorithms to buy versus build.
In principle, we try to approach AI holistically. To take into account positives and negatives, from the shiny to the mundane, and from hardware to software. Hardware has been an ongoing story within the broader story of AI for the last few years, and we feel it’s a good place to start our tour.
For the last couple of years, we have been keeping an eye on the growing list of “AI chips” vendors, i.e. companies that have set out to develop new hardware architectures from the ground up, aimed specifically at AI workloads. All of them are looking to get a piece of a seemingly ever-growing pie: as AI keeps expanding, said workloads keep growing, and servicing them as fast and as economically as possible is an obvious goal.
Nvidia continues to dominate this market. Nvidia was already in the market long before AI workloads started booming and had the acumen and the reflexes to capitalize on this by building a hardware and software ecosystem. Its 2020 move to make Arm a part of this ecosystem is under regulatory scrutiny. However, Nvidia did not remain idle in 2021.
Out of a slew of announcements made at Nvidia’s GTC event in November 2021. the ones that bring something new on the hardware level have to do with what we would argue characterizes AI’s focus in 2021 at large: inference and the edge. Nvidia introduced a number of improvements for the Triton Inference Server. It also introduced the Nvidia A2 Tensor Core GPU, a low-power, a small-footprint accelerator for AI inference at the edge that Nvidia claims offer up to 20X more inference performance than CPUs.
And what about the upstarts? SambaNova claims to now be “the world’s best-funded AI startup” after a whopping $676M in Series D funding, surpassing $5B in valuation. SambaNova’s philosophy is to offer “AI as a service”, now including GPT language models, and it looks like 2021 was by and large a go-to-market year for them.
Xilinx, on its part, claims to achieve dramatic speed-up of neural nets versus Nvidia GPUs. Cerebras claims to ‘absolutely dominate’ high-end compute and scored some hefty funding too. Graphcore is competing with Nvidia (and Google) in MLPerf results. Tenstorrent hired legendary chip designer Keller. Blaize raised $71m to bring edge AI to industrial applications. Flex Logix scored $55 million in venture backing, bringing its total haul to $82 million. Last but not least, we have a new horse in the race in NeuReality, ways to mix and match deployment in ONNX and TVM, and the promise of using AI to design AI chips. If that’s not booming innovation, we don’t know what is.
According to the Linux Foundation’s State of the Edge report, digital health care, manufacturing, and retail businesses are particularly likely to expand their use of edge computing by 2028. No wonder that AI hardware, frameworks and applications aimed at the edge are proliferating too.
TinyML, the art and science of producing machine learning models frugal enough to work at the edge, is seeing rapid growth and building out an ecosystem. Edge Impulse, a startup that wants to bring machine learning at the edge to everyone, just announced its $34M Series B funding. Edge applications are coming, and AI and its hardware will be a big part of that.
Something we called in 2020, was prominent in 2021 and will be with us for the years to come is so-called MLOps — bringing machine learning to production. In 2021, people tried to give names to various phenomena pertaining to MLOps, slice and dice the MLOps domain, apply data version control and continuous machine learning, as well as the equivalent of test-driven development for data among other things. The emphasis is shifting from shiny new models to perhaps more mundane, but practical aspects such as data quality and data pipeline management, and MLOps will continue to grow.
The other thing that’s likely to continue to grow, both in terms of sheer size as well as in number, is large language models (LLMs). Some people think that LLMs can internalize basic forms of language, whether it’s biology, chemistry, or human language, and we’re about to see unusual applications of LLMs grow. Others, not so much. Either way, LLMs are proliferating.
In addition to the “usual suspects” — OpenAI with its GPT3, DeepMind with its latest RETRO LLM, Google with its ever-expanding array of LLMs — Nvidia has now teamed up with Microsoft in the Megatron LLM. But that’s not all.
Recently, EleutherAI, a collective of independent AI researchers, open-sourced their 6 billion parameter GPT-j model. In addition, if you are interested in languages beyond English, we now have a large European language model fluent in English, German, French, Spanish, and Italian by Aleph Alpha. Wudao is a Chinese LLM which is also the largest LLM with 1.75 trillion parameters, and HyperCLOVA is a Korean LLM with 204 billion parameters. Plus, there’s always other, slightly older / smaller open source LLMs such as GPT2 or BERT and its many variations.
Beyond LLMs, both DeepMind and Google have hinted at revolutionary architectures for AI models, with Perceiver and Pathways, respectively. Pathways have been criticized for being rather vague. However, we would venture to speculate that it could be based on Perceiver. But since we’re in future tech territory, it would be an omission not to mention DeepMind’s Neural Algorithmic Reasoning, a research direction promising to marry classic computer science algorithms with deep learning.
No tour of AI, however condensed, would be complete without as much as an honorary mention to AI ethics. AI ethics has remained top of mind in 2021, and we have seen people ranging from FTC commissioners to industry practitioners each trying to address AI ethics in their own way. And let’s not forget about the ongoing boom of AI applications in healthcare, an area in which ethics should be a top priority with or without AI.
Knowledge graphs, graph databases and graph AI
We have been avid proponents of graphs of all shapes and sizes — knowledge graphs, graph databases, graph analytics, data science and AI — for a long time. So it is with mixed feeling that we report from this front. On the one hand, we have not seen much innovation, except perhaps in one area — graph neural networks. DeepMind’s Neural Algorithmic Reasoning leverages GNNs, too.
On the other hand, that’s not necessarily a bad thing, for two reasons. First, there is a major uptake of the technology in the mainstream. By 2025, graph technologies will be used in 80% of data and analytics innovations, up from 10% in 2021, facilitating rapid decision making, Gartner predicts. Reporting on use cases from the likes of BMW, IKEA, Siemens Energy, Wells Fargo, and UBS is no longer news, and that’s a good thing. Yes, there are challenges associated with building and maintaining knowledge graphs, but these challenges are, for the most part, well-understood.
As we have noted, knowledge graphs are practically a 20-year old technology whose time in the limelight seems to have come. The ways to build knowledge graphs are well-known, as well as the challenges that lie therein. It’s no coincidence that some of the most in-demand skills and areas for development in knowledge graphs are around using Natural Language Processing and visual interfaces to build and maintain knowledge graphs, as well as ways to expand from single-user to multi-user scenarios.
And to tie this conversation to the broader picture of AI where it belongs, common challenges seem to be around operationalization and building the right expertise in teams, as those skills are in very high demand. Another important touchpoint is the hybrid AI direction, which is about infusing knowledge in machine learning. Leaders such as Intel’s Gadi Singer, LinkedIn’s Mike Dillinger and Hybrid Intelligence Centre’s Frank van Harmelen all point towards the importance of knowledge organization in the form of knowledge graphs for the future of AI.
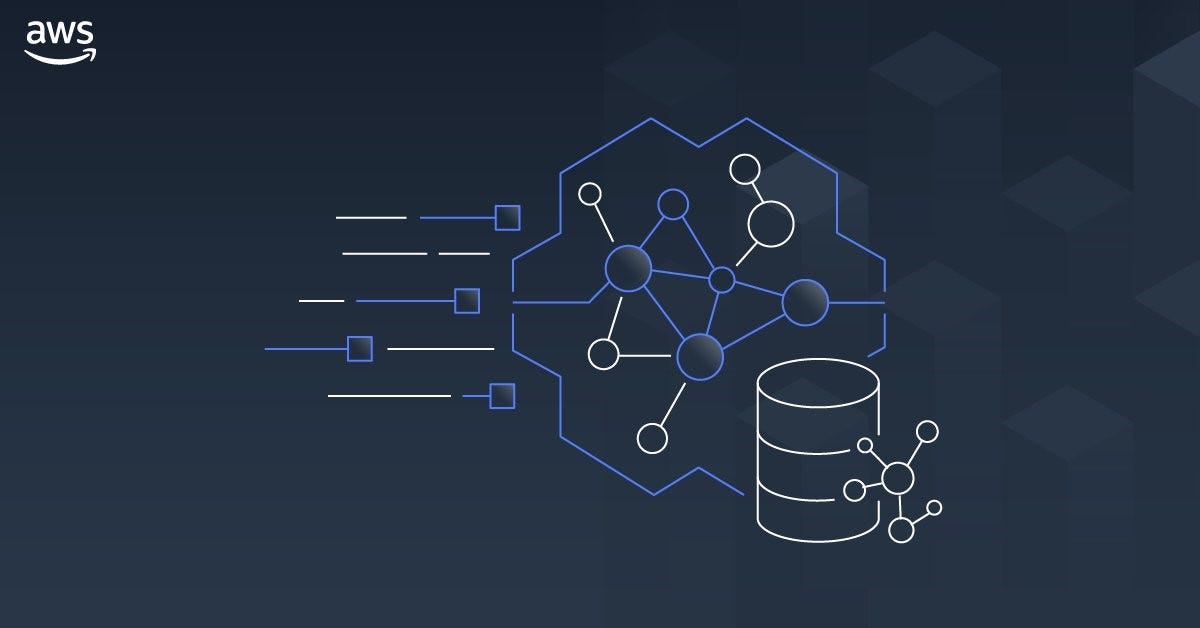
Knowledge Graphs, Graph Databases and Graph AI are all converging
AWS
There is also another important touchpoint between the broader picture in AI and knowledge graphs: data meshes and data fabrics. You’d be excused for mixing up those 2 and the plethora of data-related terms flying around these days. Simplistically, let’s just say that a data fabric is meant to serve as the technical substrate for the data mesh notion of decentralized data management in organizations. That is actually a very good match for knowledge graph technology, and a few vendors in that space have identified that and positioned themselves accordingly. Even Informatica seems to have noticed.
And what about the substrate for building knowledge graphs, namely graph databases? The word that seems to characterize 2021 for graph databases would be “go to market”. It’s been a good year for graph databases. A graph database — Neo4j — made the Top 20 in DB Engines for the 1st time. Neo4j also announced the general availability of its Aura managed cloud service and raised a $325 million Series F funding round, the biggest in database history, bringing its valuation to over $2 billion.
The graph database space saw a series of funding rounds and an upcoming IPO. TigerGraph scored $105M Series C, Katana Graph $28.5M Series A, Memgraph $9.34M seed funding and TerminusDB €3.6M. In the meantime, Bitnine, makers of Agens Graph, started working on its IPO — the first in the market.
On the technical front, GraphQL is still growing in adoption, either as part of a broader ecosystem or as the central component in a data architecture. The bridging of the two graph database worlds in terms of models, RDF and LPG, is still a work in progress, but one that has seen some interesting developments in 2021.
We don’t expect the world’s honeymoon with graphs and graph databases to last forever, and after the hype, disillusionment will inevitably follow at some point. But we are confident that this technology is foundational and will find it its place despite hiccups.