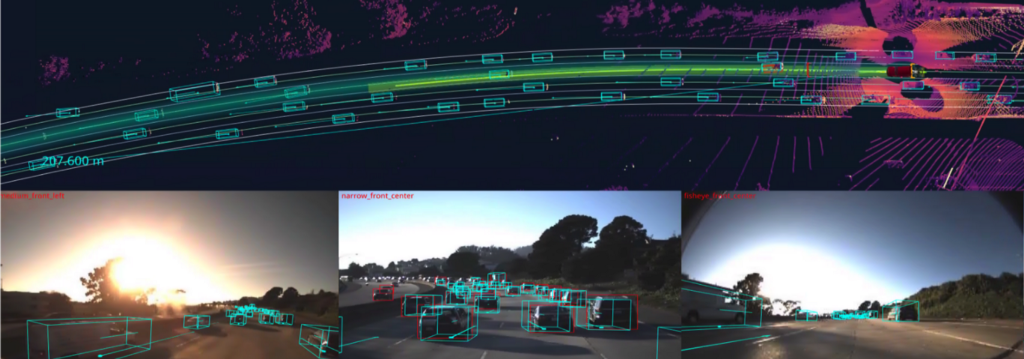
By Lance Martin and Alvin Zhang
Few industries have gained more prominence this year than logistics. With millions at home sheltering in place, there is unprecedented demand for delivery of food and other essential items. People across the country are realizing they should #ThankATrucker. At Ike, we believe automation has the potential to make trucks safer, truckers more valued, and trucking more productive. We also believe that trucks present a direct path to launching safe, reliable, and commercially-viable automated vehicles, which have held promise for decades. By focusing on freight and highway driving, we can limit the scope of the problem and avoid issues such as passenger comfort. Yet, even with this focus, many interesting technical challenges remain. Of these, one of the most difficult and central tasks is long-range object detection.
A key difference between automation for trucking (primarily highway driving) and passenger cars (primarily urban driving) is speed. A truck going 55 miles per hour needs around 150 meters to stop comfortably, which means that automated trucks must detect objects beyond this range. However, due to the industry’s historical focus on passenger cars, all of the self-driving object detection benchmarks (e.g., KITTI, NuScenes, Lyft, Waymo) feature short-range (under 100 meter) LIDAR. In contrast, long-range object detection requires sensors with long (>200 meter) detection range, such as camera, radar, and/or an emerging collection of higher-power long range LIDAR.
Furthermore, few papers have discussed the adaptation of state-of-the-art (SOTA) techniques to the challenges posed by long-range object detection. Prior to CVPR last year, we reviewed the SOTA of 3D object detection, largely discussing the trade-offs between Bird’s-Eye View (BEV) and Range View (RV) representations. With the growing interest in trucking in mind, we present an updated review of the SOTA, and discuss how these methods might be applied to long-range 3D object detection for automated trucking.
The State of the Art in 3D Object Detection
Computer vision continues to progress rapidly; CVPR 2020 boasted a record-setting 1,470 accepted papers and 127 workshop proposals. Extending last year’s blog post, we now focus on the trade-offs between grid-based (e.g., voxelization) methods and the growing collection of grid-free (e.g., point sets and graphs) methods for processing LIDAR point clouds.
Grid-Based Methods
Convolutional neural networks (CNNs) are powerful feature extractors, underpinning many of the machine learning systems achieving superhuman performance on tasks ranging from games to object classification to cancer detection. Yet, for all that, CNNs require a fixed-dimensional grid input (e.g., a 224 x 224 x 3-channel RGB image). In contrast, autonomous vehicles have historically relied heavily on LIDAR, which provides accurate object ranging but produces a sparse, irregular point cloud. Therefore, a number of approaches have been developed in order to convert LIDAR point clouds into the requisite fixed-size grid amenable to a CNN backbone.
An effective approach (used in methods such as PIXOR) is to voxelize the point-cloud into a binary occupancy grid. However, this sampling operation necessarily loses within-voxel spatial information. PointNet addresses this limitation by generating spatial encodings for each point, which are then locally aggregated within grid cells via a symmetrical operation such as max(⦁) (Figure 1). These aggregated features are often scattered back to individual points before re-encoding the grid-feature-augmented points back into grid cells, allowing the network to utilize non-local information. PointNet blocks have become increasingly common among top submissions to the KITTI leaderboard, highlighting two common themes in SOTA architectures: 1) learn, rather than hand-craft, features and 2) utilize non-local information.

Recent papers have applied these themes to the challenge of picking CNNs’ input grid resolution, which involves a trade-off between performance and speed. A finer grid captures granular geometry features and better localizes objects, but suffers from longer inference time. Therefore, several papers have introduced multi-scale feature fusion strategies (analogous to Feature Pyramid Networks or Deep Layer Aggregation for CNN feature extraction) that aggregate features across grid resolutions. Rather than using a single grid resolution, the network learns how to combine information at different scales.
For example, the Hybrid Voxel Network (HVNet) assigns points to voxels of multiple sizes, then scatters these multi-scale voxel-wise features back into points using attention (Figure 2). Similarly, PV-RCNN encodes CNN-generated features in keypoints with multiple receptive fields. HRNet even proposes a new CNN backbone which maintains both high- and low-resolution feature maps through the entire feature extraction process.

The theme of learning, rather than hand-crafting, parameters has also been applied to the task of tuning non-maximum suppression (NMS) for anchors. Anchors are used as object bounding box priors in many SOTA object detectors. NMS is then used to filter overlapping anchors, which represent duplicate detections of the same object. Both methods require hand-tuned parameters, such as anchor dimensions or an intersection-over-union (IoU) threshold. To bypass this need for parameter tuning, AFDet, which currently tops the Waymo 3D Leaderboard, extends Objects as Points (Figure 3) by using an anchor-free heatmap to identify object locations while regressing object attributes directly with five convolutional heads.

Grid-Free Methods
Although the above methods mitigate the loss of spatial information incurred by compacting LIDAR point clouds into a grid, this problem is sidestepped by a growing collection of grid-free methods which preserve the point cloud’s spatial structure. Grid-free methods often leverage PointNet to aggregate local point features into more global features while maintaining symmetry between points. Yet, grid-free methods must still choose how to group points to compute global features and store these features for further computation.
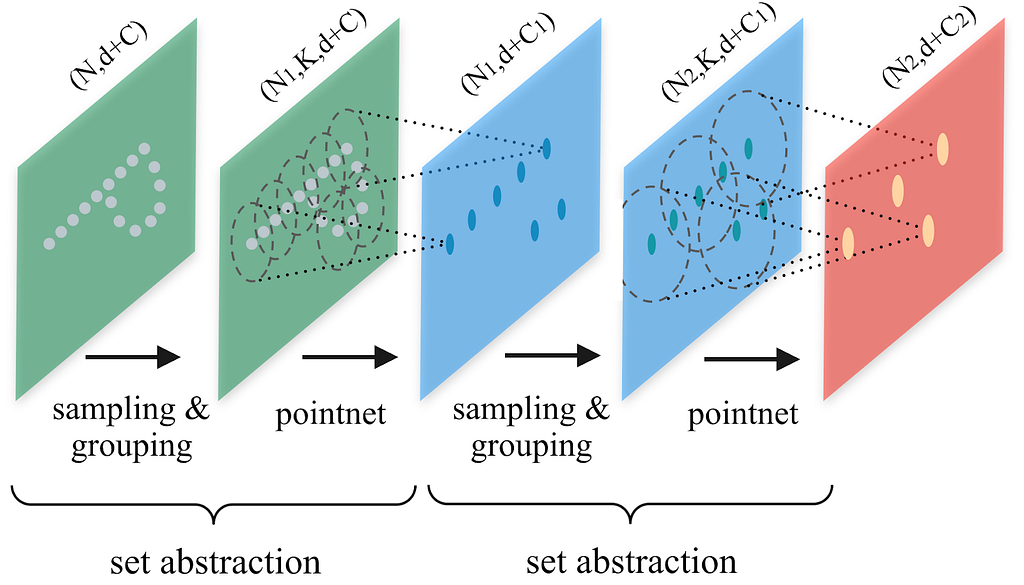
For this choice, many grid-free implementations use the set abstraction (SA) layers introduced in PointNet++ (Figure 4). Analogously to convolutional layers, SA layers can be stacked to store global features into a few adaptively sampled keypoints, which can then be used as input to yet another SA layer. Overall, PointNet++ infers global structure from local regions, supports multi-scale feature fusion, and propagates global information to local points.
Building on the PointNet++ backbone, F-Pointnet was a pioneering grid-free method for 3D object detection. Utilizing two stages (like Faster-RCNN), it first uses a 2D image-based object detector to produce object bounding box proposals, followed by a PointNet++-based stage to refine these bounding box estimates. PointRCNN follows this same two stage paradigm, but instead uses PointNet++ in the proposal generation stage. Observing that SA layers are slower than a CNN backbone, Sparse-To-Dense (STD) improves latency by voxelizing the features for each of the proposals, yielding a more compact representation that is efficiently used by fully-connected (FC) layers in the second stage. Graph-based methods, like PointGNN, similarly avoid the need for the repeated sampling and grouping operations of SA layers and report strong performance on KITTI, but have not yet been optimized for latency.
3D-SSD bucks the trend of two-stage grid-free detectors by removing the second bounding box refinement stage. To maintain performance, 3D-SSD uses an anchor-free box prediction head and adaptively samples keypoints to aggregate global features. Notably, this keypoint sampling method incorporates the feature distance between points as a criterion, improving on PointNet++ by utilizing learnable features. As a result, 3D-SSD achieves performance on par with the best two-stage detectors with twice the speed.
Hybrid Methods
As discussed above, grid-based approaches utilize an efficient CNN backbone, but incur information loss. In contrast, grid-free approaches preserve point cloud structure, but can be computationally expensive. With these trade-offs in mind, a growing set of strong performing methods have combined the benefits of the grid-based and grid-free approaches in novel ways.
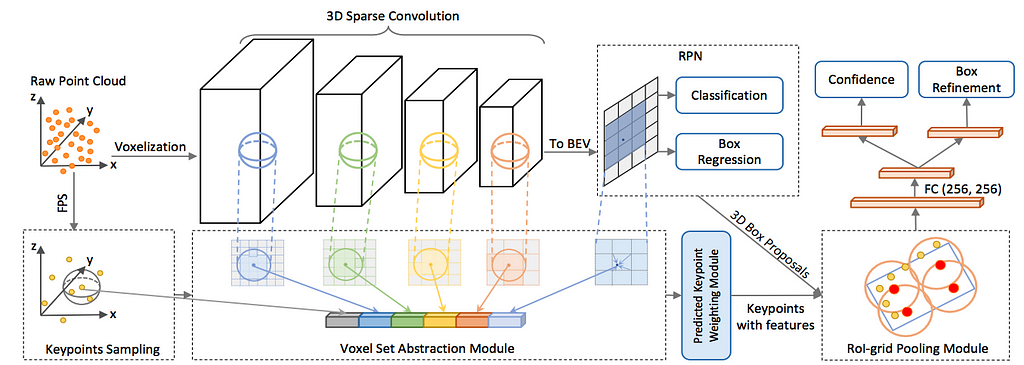
A common strategy in these “hybrid” methods is to augment a grid-based backbone with a parallel branch. The current top performer on KITTI, PV-RCNN (Figure 5), is a two-stage detector which uses a CNN to generate region proposals, while utilizing a parallel grid-free PointNet-based branch to aggregate features into keypoints. Because feature are accumulated into these adaptively chosen keypoints, PV-RCNN preserves both point-cloud structure and localization information, thereby improving accuracy in the box refinement stage. Similarly, the Structure-Aware Single-Stage Detector (SA-SSD) encourages a grid-based backbone to encode structure-aware information into learned voxelized features, using the auxiliary point-based tasks of foreground segmentation and object center estimation.
Long-Range 3D Object Detection
Although these methods show strong performance on existing benchmarks, we now outline some challenges associated with adapting them to the long-range domain required for highway driving and automated trucking.
Memory and Latency
Grid-based methods require a fixed-dimensional grid input. As the size of the grid grows for longer range detection, either resolution or memory and latency must be sacrificed. Point cloud sparsity may also waste considerable memory and computation, as up to 99.5% of the grid cells may be empty following voxelization. To address these challenges, several papers present techniques that reduce the computation and memory required to process sparse point clouds. “Submanifold” Sparse Convolutions maintain input grid sparsity through convolution operations, while SECOND and MVF introduce techniques for implementing memory-efficient sparse operations on GPU. SECOND provides a framework for efficient 1-D convolutions while MVF densely stores point features in memory, instead of scattering them throughout a mostly-empty array (Figure 6). On the other hand, grid-free methods do not waste memory and computation on empty grid cells, but they may require different optimizations to reduce the costs of repeated SA operations on larger, long-range point clouds.

A Different Perspective
Using the perspective-projected Range View (RV) is an alternate way to reduce the computational cost of a grid-based approach: unlike the top-down Bird’s Eye View (BEV), the grid size of the RV remains constant as LIDAR range increases, making the RV representation compact with potentially more information per-cell than BEV. But, as discussed in a prior post, there are trade-offs between the RV and the BEV: object size depends on distance in RV and objects can be occluded. With this in mind, Multi-View Fusion (MVF) fuses RV and BEV LIDAR representations to capture the benefits of each, generating more accurate detections (Figure 7), particularly for partially occluded objects and objects at longer range where data is more sparse.
LIDAR-Image Fusion
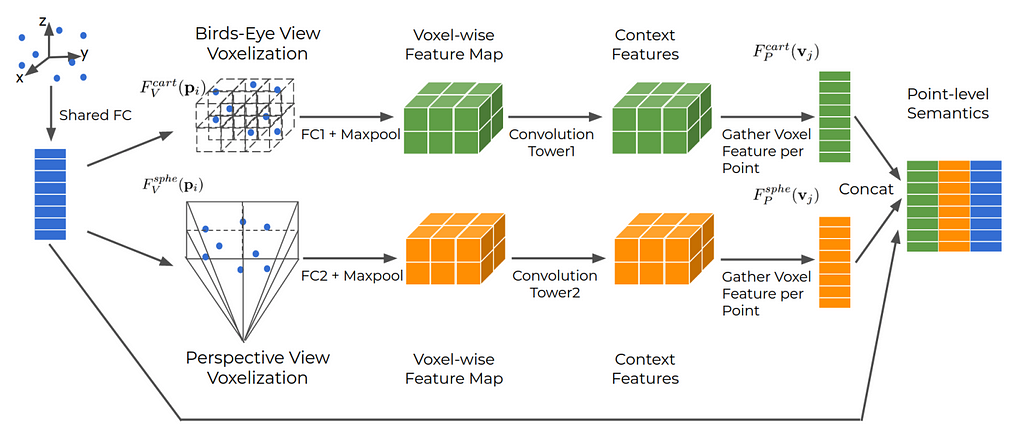
Alternatively, to address LIDAR feature sparsity at long ranges, one can fuse camera and LIDAR features. LaserNet++ (Figure 8) fuses LIDAR and camera images in the RV, achieving an impressively fast 30ms inference time due to the compact RV representation. Multi-Task Multi-Sensor Fusion (MMF) uses LIDAR points as the conduit of information between BEV LIDAR features and the image: LIDAR points are projected to RV, used to fetch image features, and projected back to the BEV grid. PointPainting follows a similar approach, but augments LIDAR points with class scores from image-based semantic segmentation. The current top-performing image-fusion model, 3D-CVF, uses multi-scale feature fusion with attention, a learned projection mapping, and feature fusion in the BEV feature maps directly. Thus, by combining sensor modalities in-network, fusion can empower the model to leverage the strengths, and compensate for the weaknesses, of both sensors.

Hallucinating LIDAR
Rather than relying on camera images to provide denser features for long-range objects, Associate-3Ddet takes the radical step of “hallucinating” LIDAR points for distant or occluded objects in BEV, an idea inspired by top-down processing in the human brain: the grid-based deformable-convolution backbone network should generate the same feature map from real-world data (sparse at long ranges) as from “conceptual” data, which has been augmented to be dense at all ranges. A twin network implements this idea (Figure 9). To generate the “conceptual” data, the authors use a nearest-neighbor like operation to substitute less-informative objects with complete objects from the annotated dataset. This approach of “hallucinating” complete object data during training shows very strong performance on the KITTI 3D leaderboard (currently #3) while preserving low (40ms) latency.
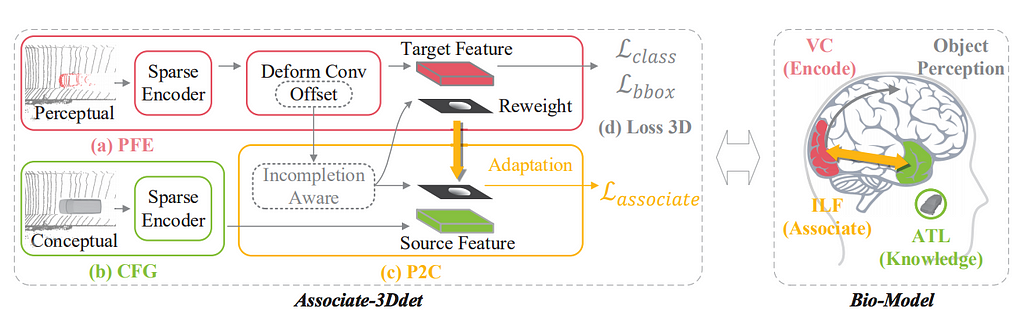
Image-Only
Image-based 3D detection architectures eliminate or limit the need for a costly long-range LIDAR, but currently lag the performance of LIDAR-based detectors on benchmarks. Yet, progress is encouraging: PseudoLIDAR converts a stereo depth map to a point cloud representation, which can be fed as a BEV image to SOTA LIDAR-based detectors (Figure 10). PseudoLIDAR++ builds on this work by using sparse returns from an inexpensive 4-beam LIDAR to correct systematic errors in the pseudo-LIDAR point cloud. The performance of these methods at the detection range required for trucking should be carefully evaluated, but advances on this front are promising.

Summary
Two themes underpin many of SOTA methods: 1) learn, rather than hand-craft, features and 2) utilize non-local information. We see this reflected in the fact that many top 3D object detection methods, whether grid-based or grid-free, use a learned point encoder to generate spatial-structure-aware features from raw LIDAR points. Similarly, grid-based and grid-free methods use non-local information (via multi-scale feature fusion) to infer global features from local information while giving global context to local regions.
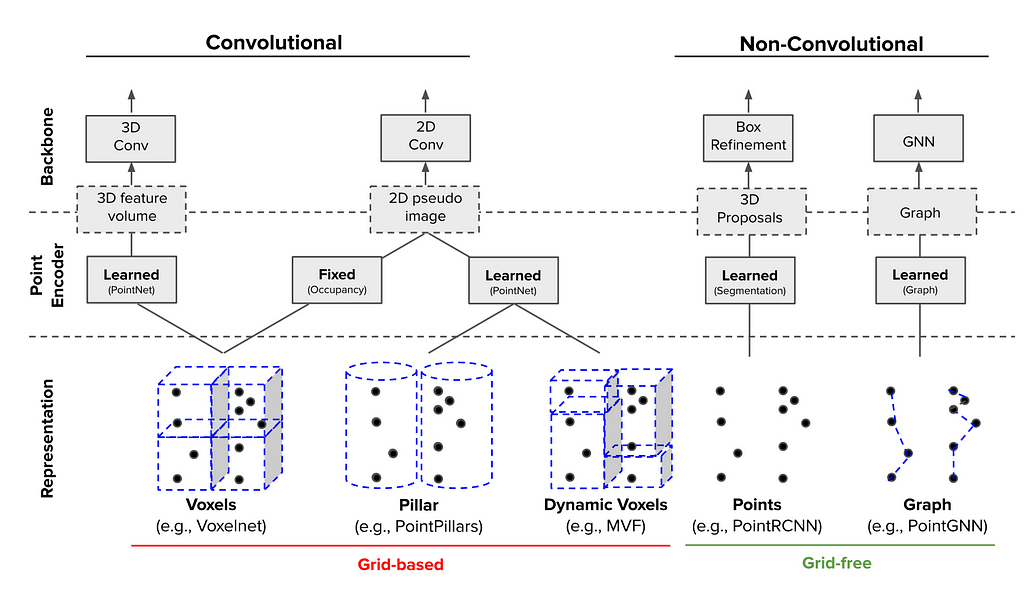
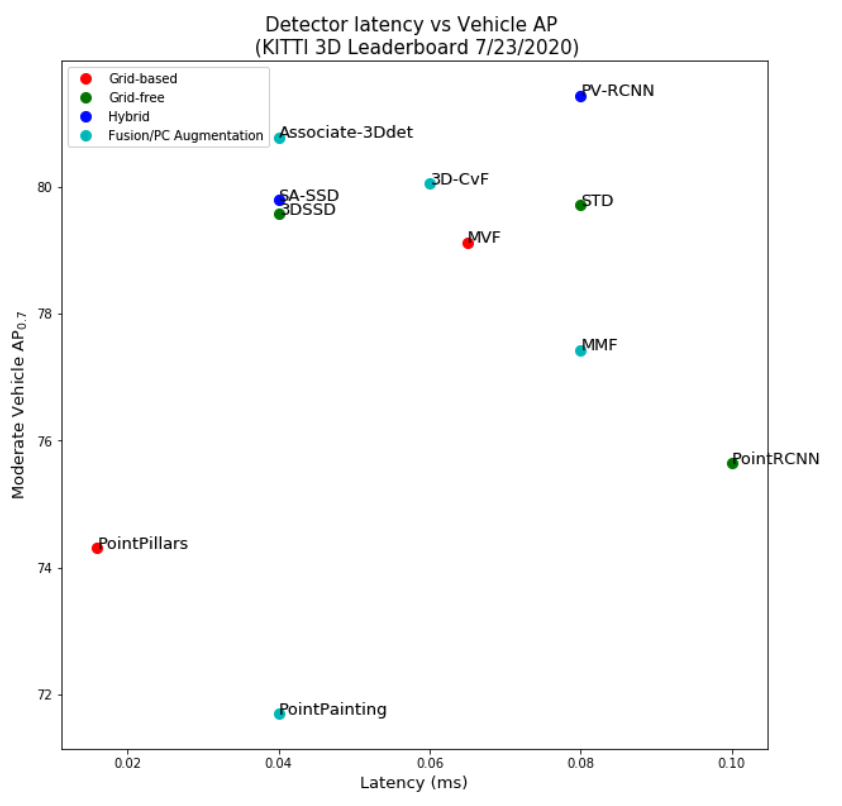
In general, grid-based methods are over-represented on the leaderboard, which is likely due to researcher familiarity with, and dedicated infrastructure for, CNNs. But, the line between grid-based and grid-free methods appears to be blurring, as recent top-performing methods, (such as PV-RCNN, STD, and SA-SSD) combine the high efficiency of grid-based CNN or FC backbones with the point-cloud-structure-preserving properties of grid-free techniques.
When considering the application of these methods to long-range object detection, we have identified a number of optimizations addressing the LIDAR point cloud sparsity. We also discussed a number of ideas that augment sparse LIDAR data at long ranges, such as LIDAR-based range-view (RV) fusion, early image fusion, and “hallucinating” dense LIDAR features. Finally, generating a pseudo-LIDAR point cloud directly from images may provide a powerful way to densify sparse LIDAR data and / or entirely replace the need for LIDAR.
Despite the promise of automated trucking, there remains no public way to evaluate new ideas for long-range object detection in the context of highway driving. Public benchmarks and leaderboards, such as ImageNet, have been a catalyst for important and unexpected innovation in many areas of machine learning; Fei-Fei Li began work on ImageNet in 2006, over a half-decade before the debut of AlexNet. Numerous challenges, most notably KITTI, play a similar role for urban automation today. With these examples in mind, a public object detection benchmark for the long range / trucking domain would be a beneficial contribution to the community and spur innovation towards this technically demanding and socially important problem.
Figure References
[1] M. Ye, S. Xu, and T. Cao, “HVNet: Hybrid Voxel Network for LiDAR Based 3D Object Detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 1631–1640, link.
[2] Xingyi Zhou, Dequan Wang, and Philipp Krhenbhl. Objects as points. arXiv preprint arXiv: 1904.07850, 2019, link.
[3] C. R. Qi, L. Yi, H. Su, and L. J. Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. arXiv preprint arXiv:1706.02413, 2017, link.
[4] Shi, S., Guo, C., Jiang, L., Wang, Z., Shi, J., Wang, X., Li, H.: Pv-rcnn: Point-voxel feature set abstraction for 3d object detection. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10529–10538 (2020), link.
[5] Yin Zhou, Pei Sun, Yu Zhang, Dragomir Anguelov, Jiyang Gao, Tom Ouyang, James Guo, Jiquan Ngiam, and Vijay Vasudevan. End-to-end multi-view fusion for 3d object detection in lidar point clouds. arXiv preprint arXiv:1910.06528, 2019, link.
[6] Gregory P Meyer, Ankit Laddha, Eric Kee, Carlos Vallespi-Gonzalez, and Carl K Wellington. Lasernet: An efficient probabilistic 3d object detector for autonomous driving. In CVPR, 2019b, link.
[7] Liang Du, Xiaoqing Ye, Xiao Tan, Jianfeng Feng, Zhenbo Xu, Errui Ding and Shilei Wen. Associate-3Ddet: Perceptual-to-Conceptual Association for 3D Point Cloud Object Detection. arXiv preprint arXiv: 2006.04356, 2020, link.
[8] Yan Wang, Wei-Lun Chao, Divyansh Garg, Bharath Hariharan, Mark Campbell, and Kilian Q. Weinberger. Pseudo-lidar from visual depth estimation: Bridging the gap in 3d object detection for autonomous driving. In CVPR, 2019, link.
Perception for Automated Trucking was originally published in Ike Blog on Medium, where people are continuing the conversation by highlighting and responding to this story.